
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



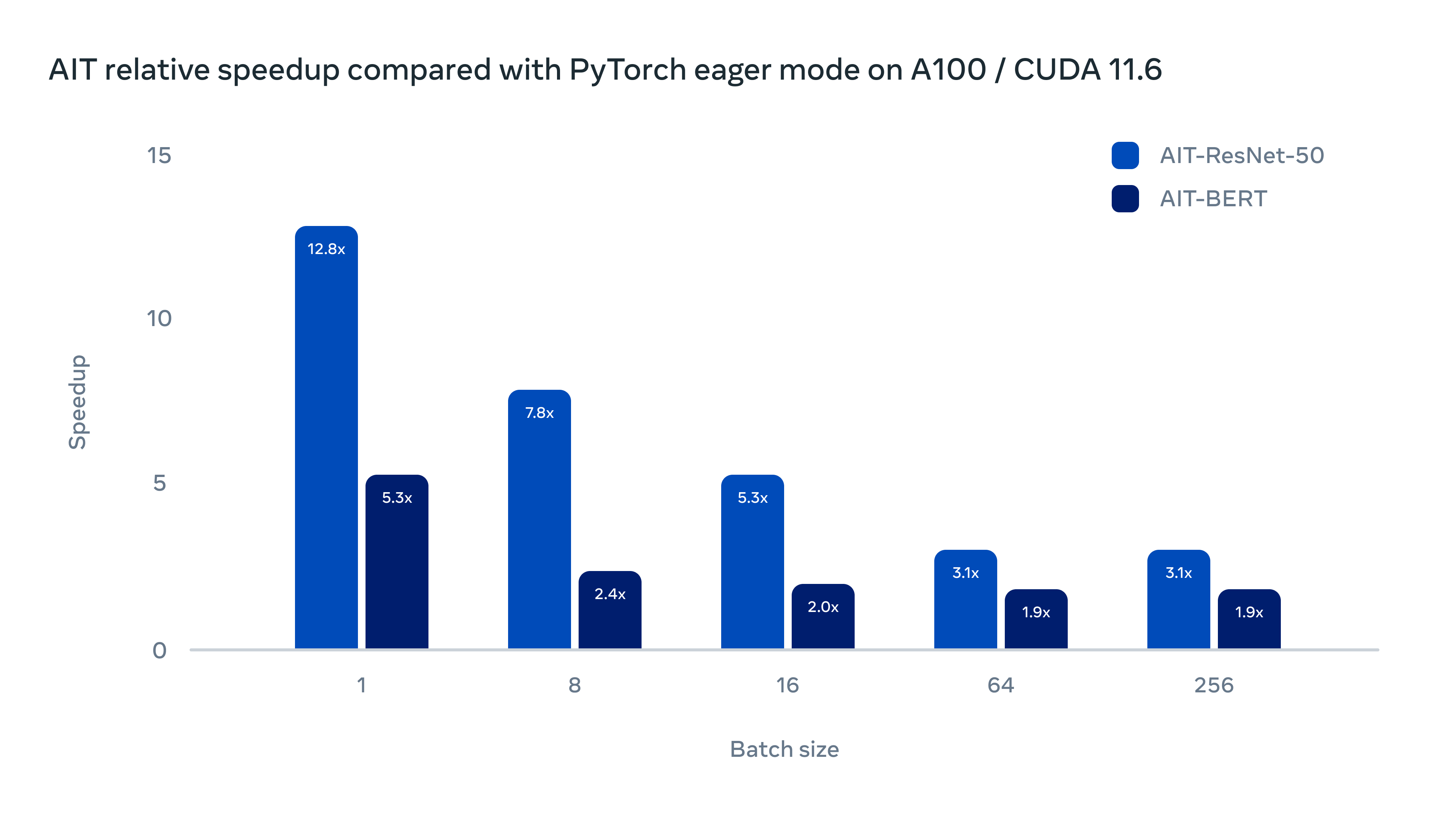
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。

5月4日,网络流传了一个所谓Google内部人员写的内部信,表达了Google和OpenAI这样的公司可能并不能在AI领域获得胜利的焦虑。里面说明了开源的AI模型发展迅速,不管是Google还是OpenAI都没有很好的护城河。

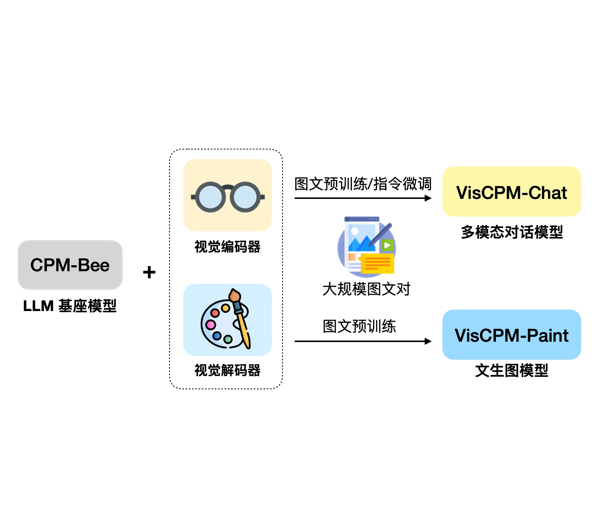
大模型的发展正在从单纯的语言模型向多模态大模型快速发展。尽管GPT-4号称也是一个多模态大模型,但是受限于GPU资源,GPT-4没有开放任何多模态的能力(参考:https://www.datalearner.com/blog/1051685866651273 )。目前大家所能接触到的多模态大模型很少。今天,清华大学NLP小组带来了新的选择,发布了VisCPM系列多模态大模型。VisCPM系列包含2类多模态大模型,分别针对多模态对话和文本生成图片进行优化。

最近,随着DeepSeek R1的火爆,推理大模型也进入大众的视野。但是,相比较此前的GPT-4o,推理大模型的区别是什么?它适合什么样的任务?推理大模型是如何训练出来的?很多人并不了解。本文将详细解释推理大模型的核心内容。
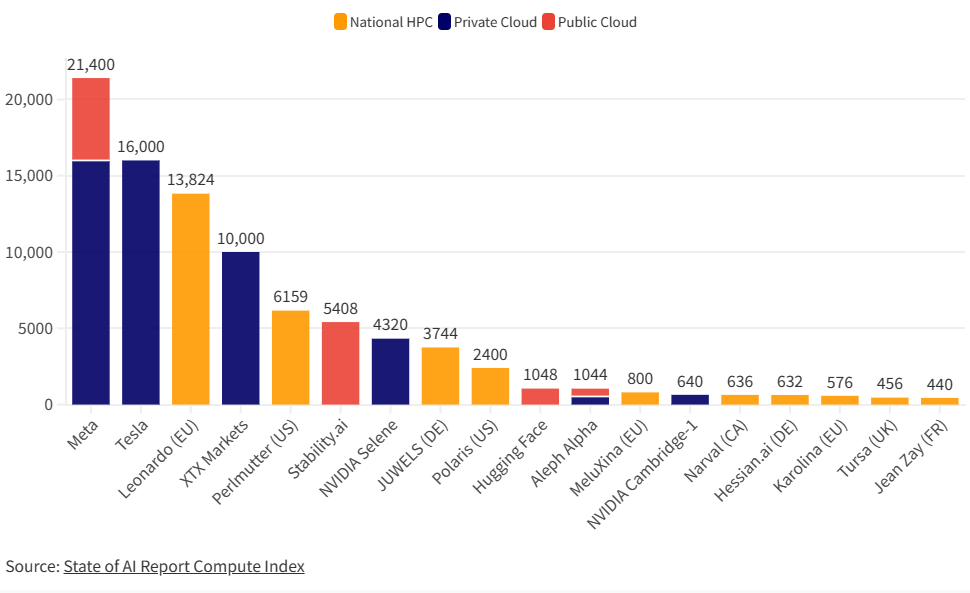
在高性能计算(HPC)、人工智能(AI)、和数据分析等领域,图形处理器(GPUs)正在发挥越来越重要的作用。其中,NVIDIA的 A100尤为引人注目。这是英伟达最强大的显卡处理器,也是当前使用最广泛大模型训练用的显卡。本文主要是各大企业最新的2023年9月份拥有的显卡数量统计。
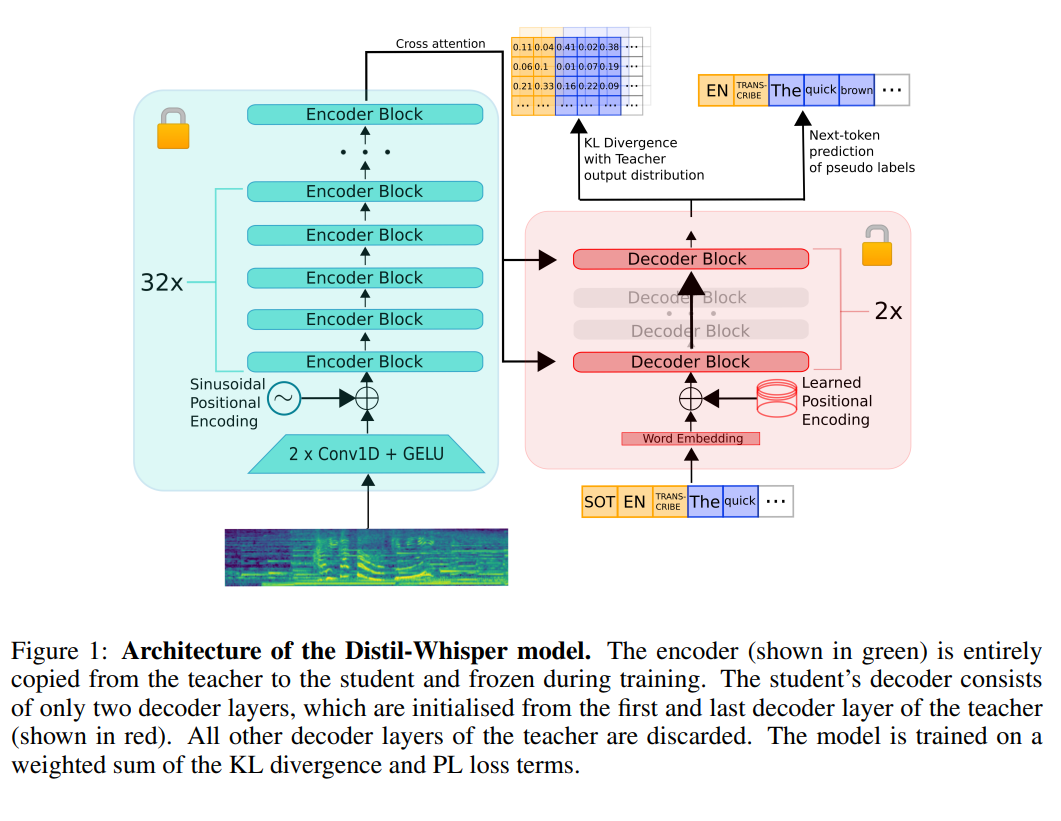
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。
大语言模型是通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型。但是,当前大家讨论较多的都是语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。

在今年的Microsoft Build 2023大会上,来自OpenAI的研究员Andrej Karpathy在5月24日的一场汇报中用了40分钟讲解了ChatGPT是如何被训练的,其中包含了训练一个能支持与用户对话的GPT的全流程以及涉及到的一些技术。信息含量丰富,本文根据这份演讲总结。
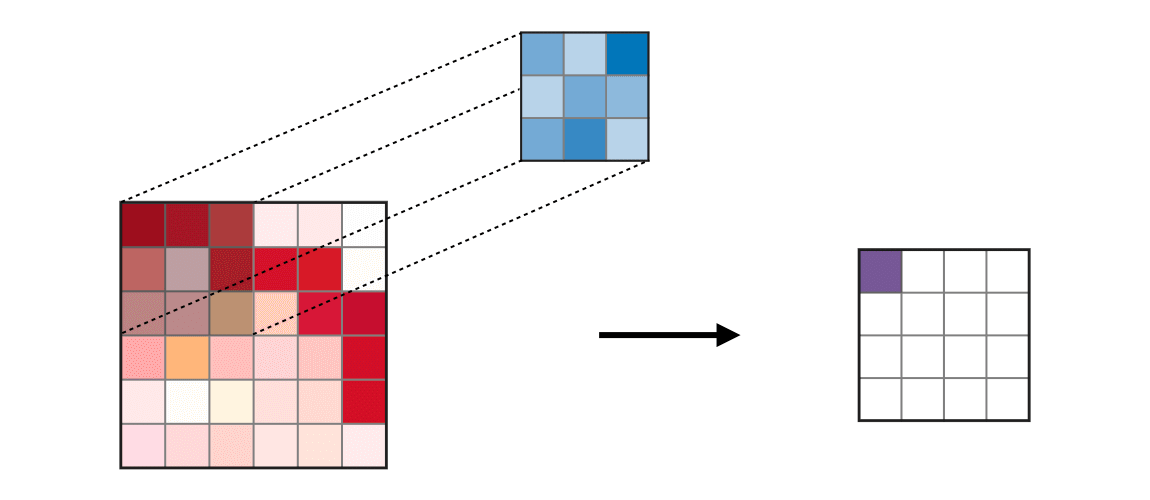
CS 230 ― Deep Learning是斯坦福大学视觉实验室(Stanford Vision Lab)的Shervine Amidi老师开设的深度学习课程,他在课程网站上挂了一个关于深度学习示意图的网站,这里面包含了各种深度学习相关概念的示意图和动图,十分简单明了。

今日推荐
可能是过去三十年来编程语言最大的革新:新的面向AI的编程语言Mojo发布~
斯坦福大学发布2023年人工智能指数报告——The AI Index 2023
OpenRouterAI:一个提供目前最优秀大模型API的网站,支持GPT-4 32k和Claude v2接口!
主题模型结合词向量模型(Improving Topic Models with Latent Feature Word Representations)
GPT-4在11月份以来变懒的原因可能已经找到:大模型可能会在节假日期间变得不愿意干活,工作日期间却更加高效
又一个国产开源大模型发布:前腾讯创始人创业公司元象发布XVERSE-13B,超过Baichuan-13B,与ChatGLM2-12B齐平!但免费商用授权!
使用sklearn做高斯混合聚类(Gaussian Mixture Model)
没有显卡也没关系!基于Google Colab免费GPU额度部署Stable Diffusion XL模型,可以生成4K的图!