
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。
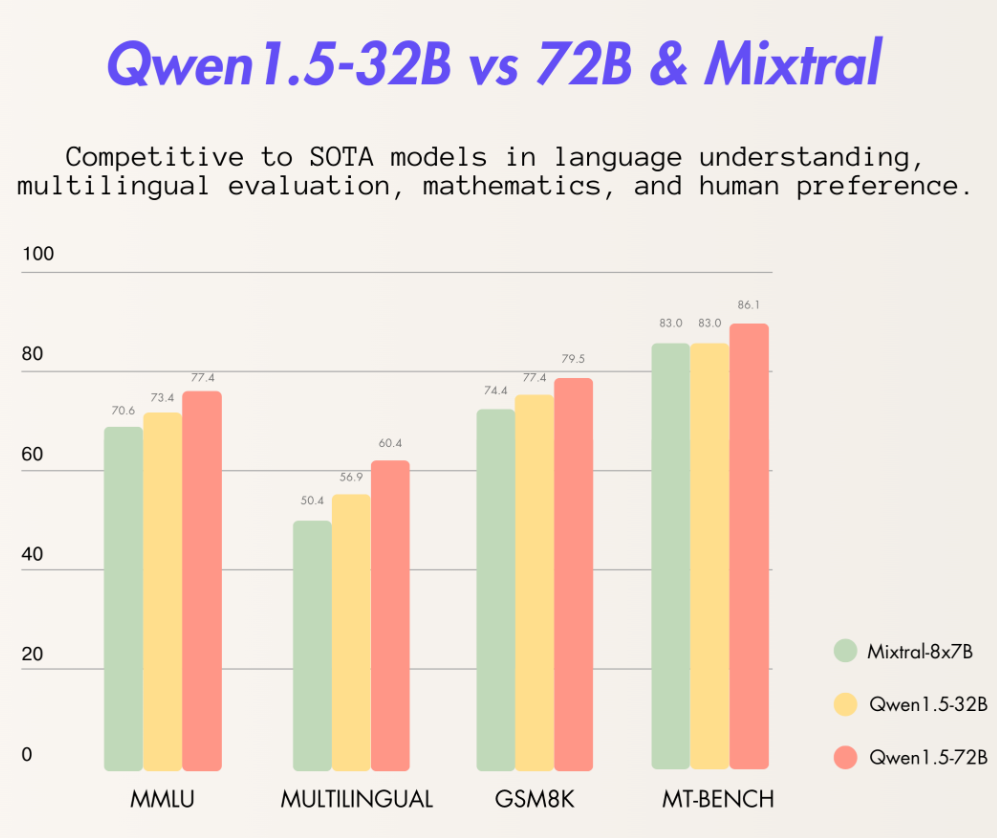
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。

本篇是《阿里云天池大赛赛题解析-机器学习篇》的第一部分工业蒸汽量预测的第三章-特征工程的内容,并附带了一些知识点的网页链接。内有数据预处理、特征降维等内容。

Stable Diffusion是一种功能强大的开源文本到图像(Text-to-Image)生成模型。虽然目前有多个开源项目可以实现基于文本提示(prompt)创建图像,但Stable Diffusion性能极其强大,其结果甚至可以媲美DALL·E2。而现在KerasCV提供了这个模型的官方实现!

自从苹果发布M1系列的自研芯片开始,基于ARM架构的电脑处理器开始大放异彩。而强大的M1芯片的能力也让很多Mac用户高兴很久。而就在现在,M1也开始支持PyTorch的深度学习框架了。PyTorch官网刚刚宣布,经过和Apple的Metal工程师队伍的合作,PyTorch支持Mac的GPU加速了。

最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。

在去年12月2日的PyTorch大会上(参考链接:[重磅!PyTorch官宣2.0版本即将发布,最新torch.compile特性说明!](https://www.datalearner.com/blog/1051670030665432
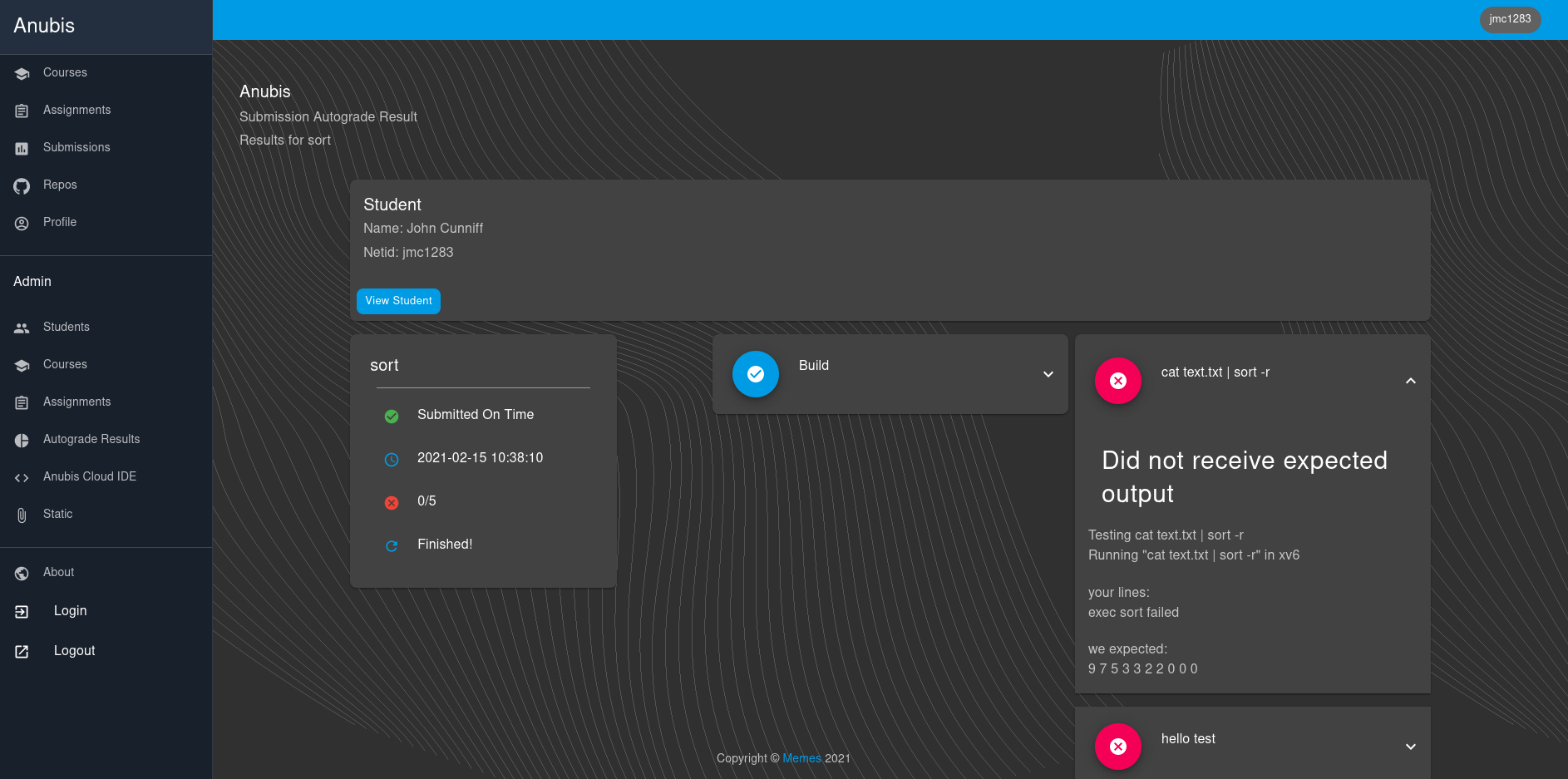
Anubis是一个分布式LMS(学习管理系统),由John Cunniff创建,专门为CS课程的自动化而设计。Anubis已经在纽约大学坦登分校使用并经过了几个学期的测试。这个系统的主要目的是自动为提交的作业评分,并提供了一个云IDE解决方案,以简化学生的体验。
自从2019年OpenAI开始商业化以来,OpenAI的成果越来越封闭,而商业化的进程越来越快。GPT系列的发展正好印证了这个路径。GPT最初的版本包含了论文、代码和预训练结果。GPT-2刚开始也认为可能会造成不好的伤害而在论文官宣了大半年之后才公布了完整模型。到GPT-3的时候也就给了官方介绍博客和论文,模型则是彻底闭源且开始商业化。而今天OpenAI直接官方博客宣布GPT-3.5商业化,连论文都没有了!

在深度学习和计算机视觉的发展历程中,视频生成技术一直是一个极具挑战和创新的领域。而发布了一系列开源领域最强图像生成模型Stable Diffusion系列模型背后的企业StabilityAI最近又开源了一个的文本生成视频大模型Stable Video Diffusion模型,这个模型可以生成最多20帧的视频。测试效果,这个模型普通版本与runway差不多,20帧版本则超过了runway!
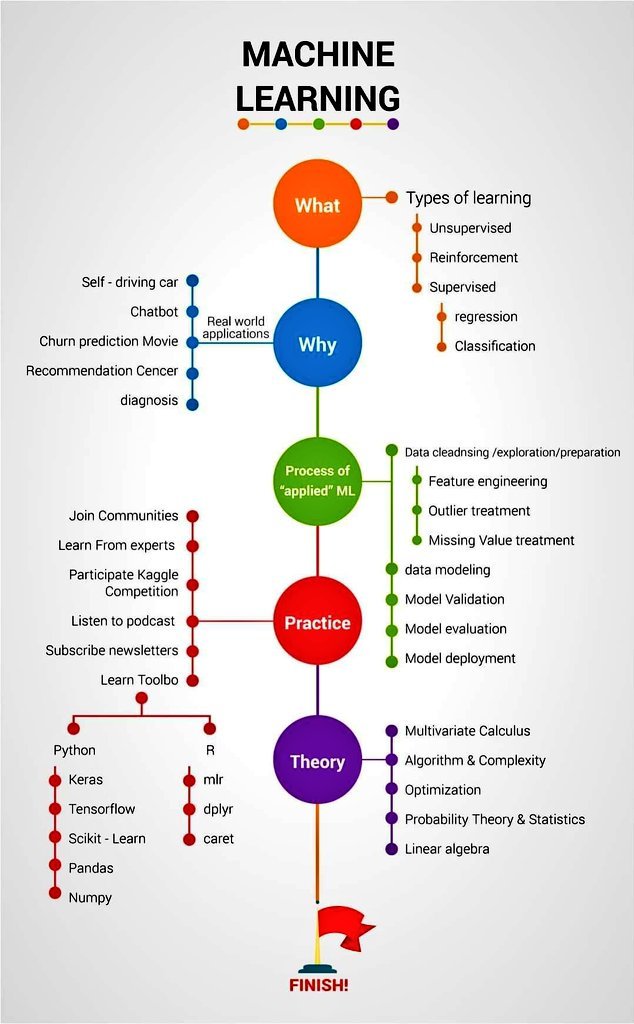
这是推特上Ternium的CIO发的一个图,关于机器学习理论和实践概念的信息图。这个图概括了机器学习实践流程的相关概念,简洁明了。对于入门的同学有很好的总结作用。
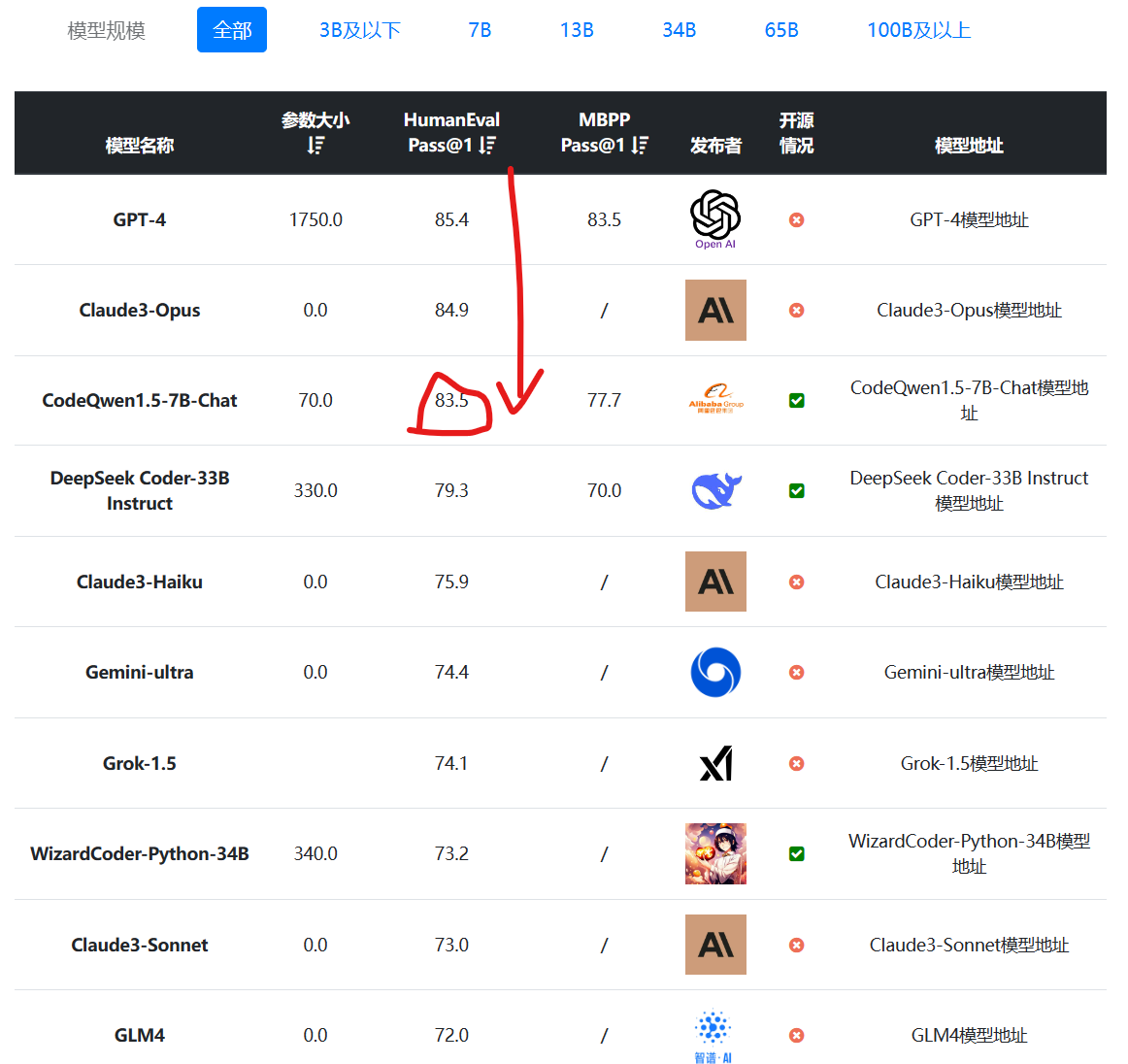
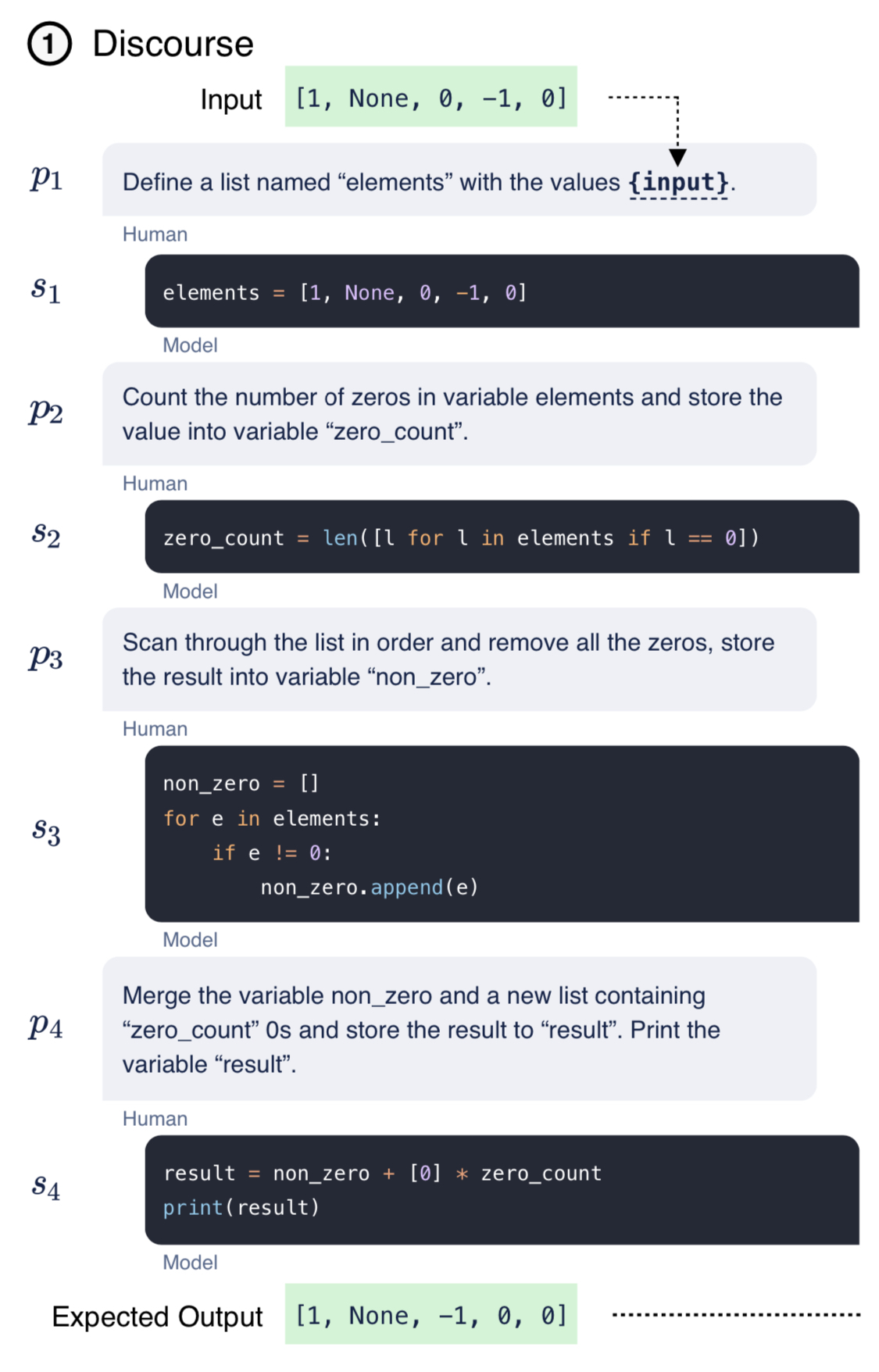
编程大模型是当前大语言模型里面最重要的一类。一般是基础大模型在预训练之后,加入代码数据集继续训练得到。在代码补全、代码生成方面一般强于常规的大语言模型。阿里最新开源的70亿参数大模型CodeQwen1.5-7B在HumanEval评测结果上超过了GPT-4早期版本,表现异常地好!
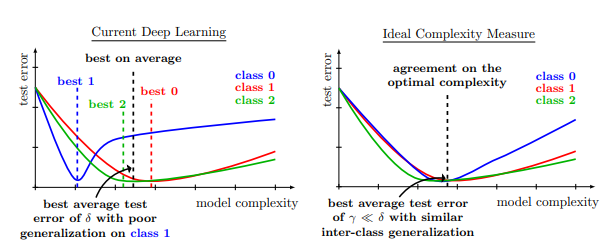
正则化是一种基本技术,通过限制模型的复杂性来防止过度拟合并提高泛化性能。目前的深度网络严重依赖正则化器,如数据增强(DA)或权重衰减,并采用结构风险最小化,即交叉验证,以选择最佳的正则化超参数。然而,正则化和数据增强对模型的影响也不一定总是好的。来自Meta AI研究人员最新的论文发现,正则化是否有效与类别高度相关。
随着华为被美国多轮制裁,大家忽然发现原来国内在半导体硬件方面的差距居然如此之大。半导体硬件相关方面的关注度前所未有,为了更好地理解计算机运行的原理,本文翻译自耶鲁大学的PCLT网站,旨在介绍关于计算机运行的一些原理知识。