
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




嵌入(Embedding)是深度学习方法处理自然语言文本最重要的方式之一。它将人类的自然语言和文本转换成一个浮点型的向量。向量之间的距离代表了它们的关系。今天,OpenAI宣布了他们的Embedding新模型——text-embedding-ada-002。官方宣称这是目前OpenAI最强的嵌入模型,可以将任意文本转换成一个向量,且效果好于目前所有OpenAI的模型。
OpenAI在其官方GitHub上公开了一个最新的开源Python库:tiktoken,这个库主要是用力做字节对编码的。相比较HuggingFace的tokenizer,其速度提升了好几倍。
字节对编码(Byte Pair Encoder,BPE),又叫digram coding,是一种在自然语言处理领域经常使用的数据压缩算法。在GPT系列模型中都有用到。主要是将数据中最常连续出现的字节(bytes)替换成数据中没有出现的字节的方法。该算法首先由Philip Gage在1994年提出。在这篇博客中我们将简单介绍一下这个方法。

Visual Studio Code简称VS Code,是由微软开发的跨平台免费开源的源代码编辑器。相比较Eclipse、PyCharm等软件,它很轻量,并不太像一个完整的IDE(Integrated Development Environment,集成开发环境)。但是,由于其轻量、快速、第三方扩展生态强大等原因,在2015年推出之后就迅速发展成为最受欢迎的开发环境。2019年的Stack Overflow的开发者调查中名列第一,使用占比月50.7%。

OpenAI是全球最著名的人工智能研究机构,发布了许多著名的人工智能技术和成果,如大语言模型GPT系列、文本生成图片预训练模型DALL·E系列、语音识别模型Whisper系列等。由于这些模型在各自领域都有相当惊艳的表现,引起了全世界广泛的关注。

刚刚,StabilityAI宣布Stable Diffusion2.1发布。距离Stable Diffusion2.0大版本发布刚2个星期,2.1版本就发布了,2.1版本有诸多改进功能。
Whisper是由Open AI训练并开源的语音识别模型,它在英语语音识别方面接近人类水平的鲁棒性和准确性。该模型于2022年9月21日发布之后引起了广大的关注。由于模型的准确性太过惊人,大家已经认为可以直接用于视频的配音制作了。而今天有人发现Whisper的GitHub上有了一个新的提交记录,显示Whisper V2版本即将来临。
12月1日OpenAI官宣了其目前最强的AI对话系统之后,大家发现这个强大的系统能做的事情远超过大家的想象。我们也在第一时间发布了相关的博客:https://datalearner.com/blog/1051669904657253 。由于这个系统实在是太过强大,大家发现的能力越来越强。连Musk也在几个小时之前感叹这个系统是so much better at bullshit than they are!在这篇博客中,我们将收集关于这个系统目前的使用案例,给大家一个更加全面的展示结果。
2022年的PyTorch Conference在新奥尔良举办。刚刚会上的keynote官宣PyTorch2.0版本即将到来。PyTorch是目前最流行的深度学习框架之一,它的易用性被广大的用户所喜爱。关于PyTorch2.0,官方透露了一些值得期待的特性。
今天,OpenAI公布了最新的一个基于AI的对话系统ChatGPT,是基于GPT3.5微调的结果,试用显示效果惊人!
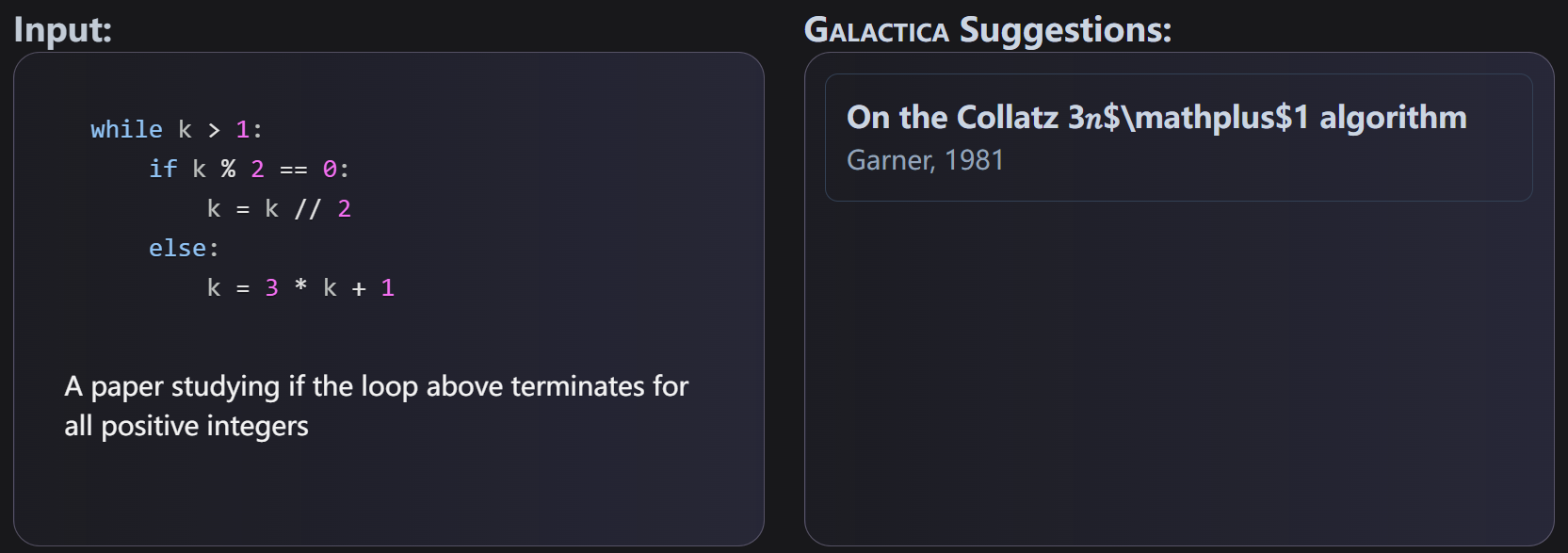
自然语言处理预训练大模型在最近几年十分流行,如OpenAI的GPT-3模型,在很多领域都取得了十分优异的性能。谷歌的PaLM也在很多自然语言处理模型中获得了很好的效果。而昨天,PapersWithCode发布了一个学术论文处理领域预训练大模型GALACTICA。功能十分强大,是科研人员的好福利!
近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。
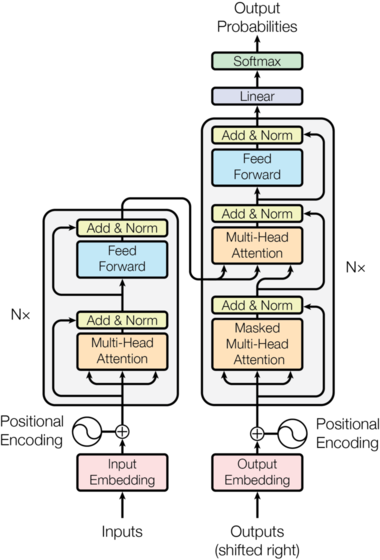
The Annotated Transfomer是哈佛大学的研究人员于2018年发布的Transformer新手入门教程。这个教程从最基础的理论开始,手把手教你按照最简单的python代码实现Transformer,一经推出就广受好评。2022年,这个入门教程有了新的版本。

Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。
今日推荐
未经证实的GPT-4技术细节,关于GPT-4的参数数量、架构、基础设施、训练数据集、成本等信息泄露,仅供参考
OpenAI开源GPT-2的子词标记化神器——tiktoken,一个超级快的(Byte Pair Encoder,BPE)字节对编码Python库
检索增强生成中的挑战详解:哪些因素影响了检索增强生成的质量?需要如何应对?
康奈尔大学发布可以在一张消费级显卡上微调650亿参数规模大模型的框架:LLMTune
Batch Normalization应该在激活函数之前使用还是激活函数之后使用?
开源大语言模型再次大幅进步:微软团队开源的第二代WizardLM2系列在MT-Bench得分上超过一众闭源模型,得分仅次于GPT-4最新版