开源利器!一个文件实现完整的强化学习算法
很多算法的开源实现都包含多个文件,因此,学习这些开源代码的时候通常难以找到入口,也无法快速理解作者的逻辑,对于学习的童鞋来说都带来了不小的挑战。这里推荐一个非常优秀的强化学习开源库,它将经典的强化学习算法都实现在一个文件中,想要学习源代码的童鞋只需要看单个文件即可,这就是ClearRL!
ClearRL的作者是美国Drexel University的计算机博士生,他主要的研究方向是游戏中的人工智能。这也是强化学习应用最好的领域之一了。这个项目从2019年10月份开始,已经更新了两年半的时间了。CleanRL是一个深度强化学习库,它提供了高质量的单文件实现,具有研究用的功能。尽管这些算法的实现非常简洁,但作者在AWS Batch将其扩展到运行成千上万的实验,依然十分有效。
CleanRL的突出特点是: 📜单一文件的实现:关于一个算法的每一个细节都被放在算法自己的文件中。因此,它更容易充分理解一个算法,并进行研究。 📊 基准化实现(7种以上的算法和34种以上的游戏,https://benchmark.cleanrl.dev) 📈 Tensorboard记录 🪛 通过设置seeding可以复现算法运行过程所有细节 🎮 可以保留游戏过程的视频 🧫 基于Weights & Biases进行实验管理 💸 与docker和AWS的云整合
目前ClearRL实现的算法如下:
同时,ClearRL还提供了一个可视化的benchmark,可以追踪所有算法的实验,里面可以看到GPU的利用率以及游戏的视频情况。
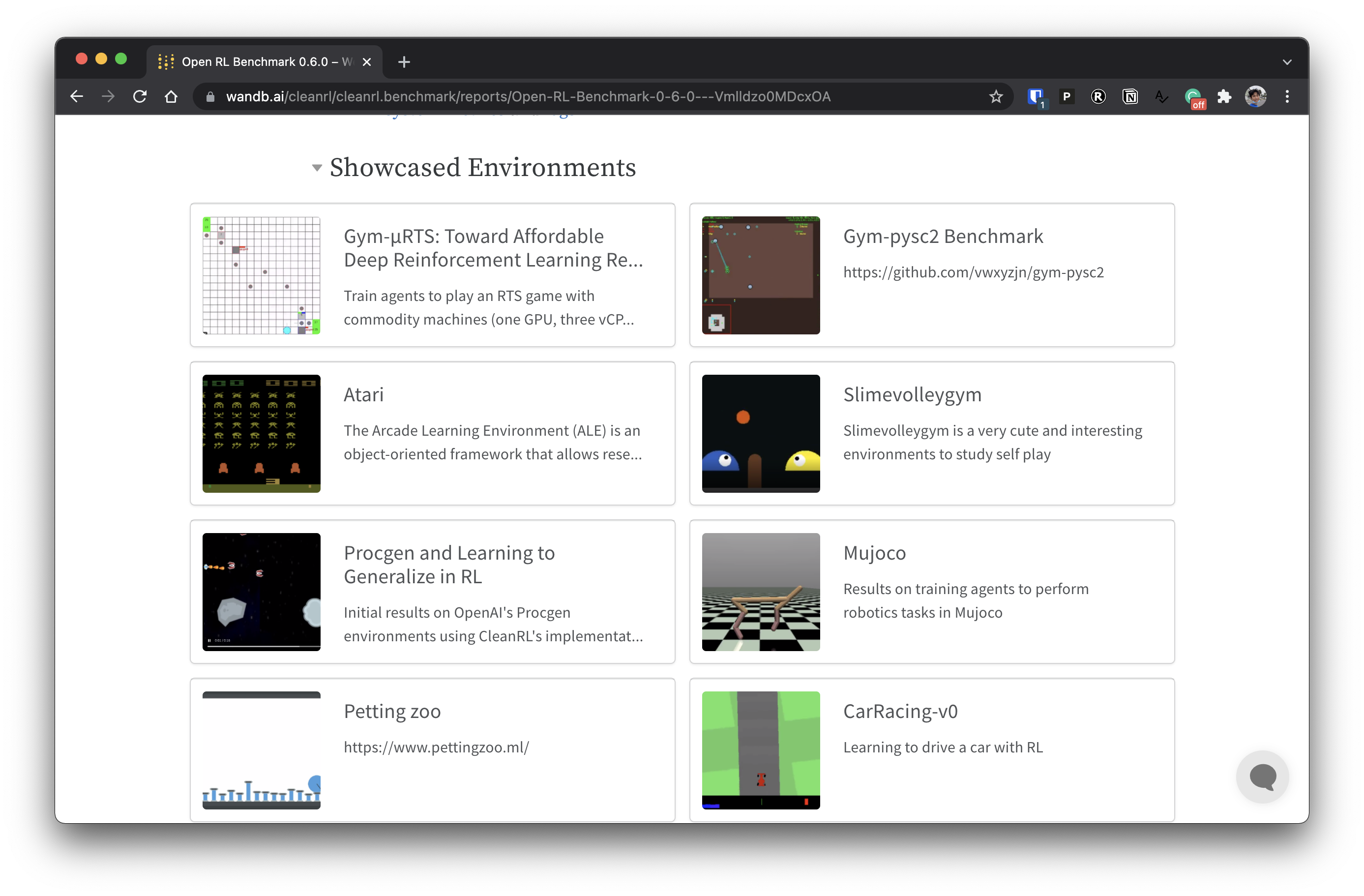
总之,这个项目对于想学习强化学习算法的童鞋来说真的是一个大福利,非常推荐学习。也可以看到,这位博士所在的课题组可能一开始进入RL领域就要求大家理解这些基本算法,而他把这个学习的过程变成一个项目也是非常好的思路。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
