
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



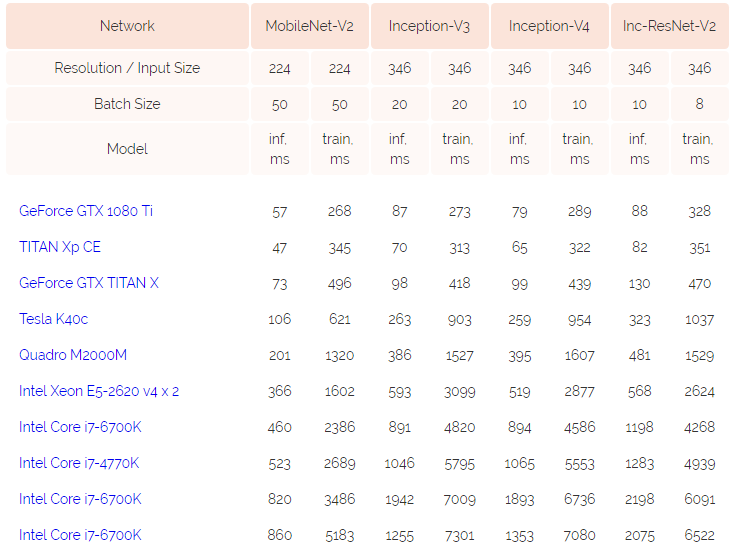

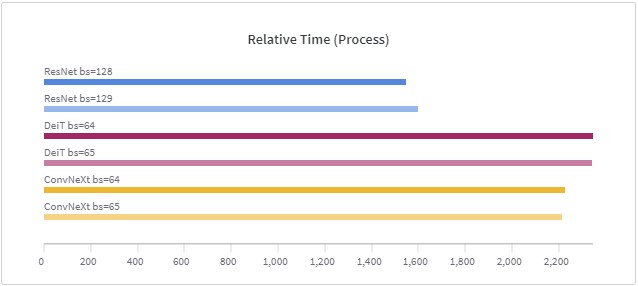
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。
本文是Effective Java第三版笔记的第二个之当构造参数很多的时候考虑使用builder

刚刚,StabilityAI宣布Stable Diffusion2.1发布。距离Stable Diffusion2.0大版本发布刚2个星期,2.1版本就发布了,2.1版本有诸多改进功能。
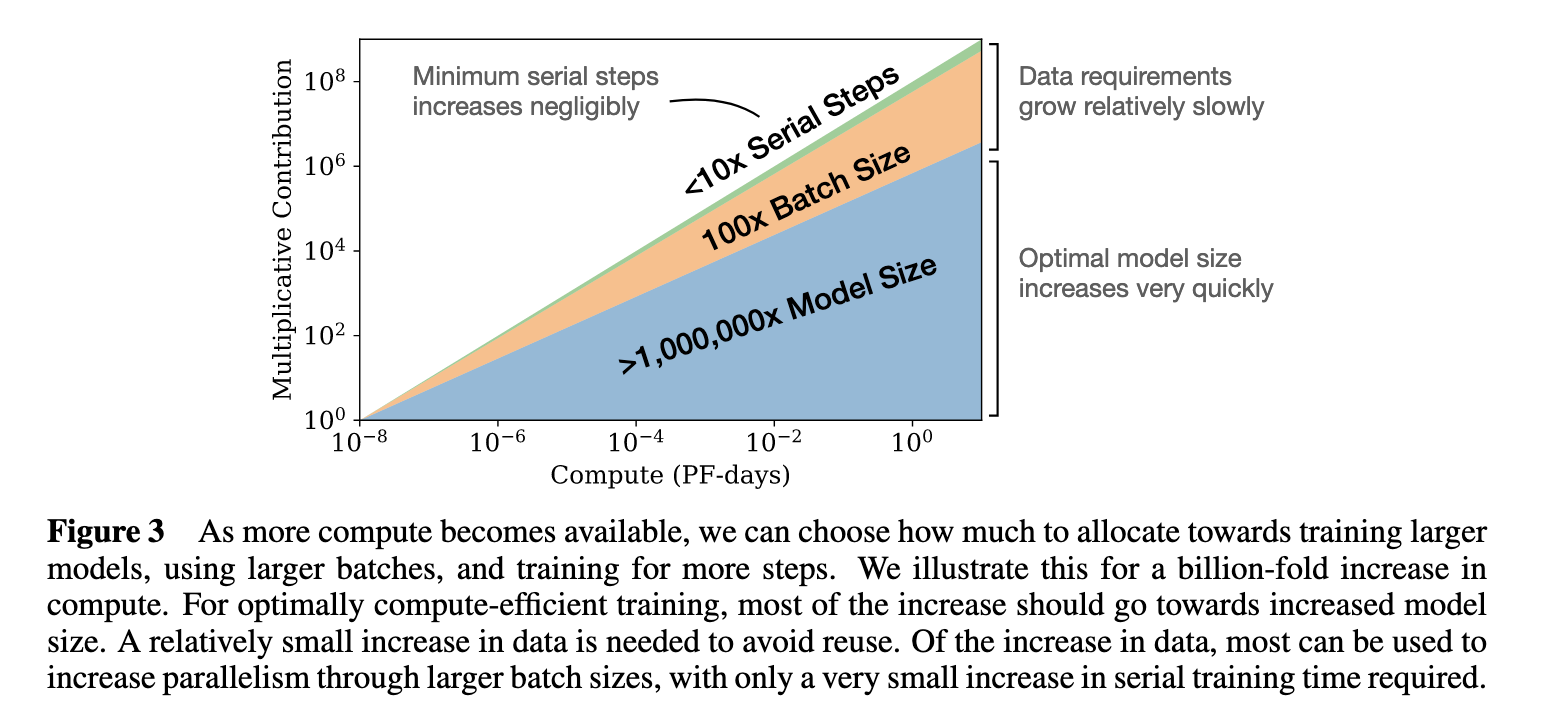
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。并提出了新的模型缩放规律。

昨天,HuggingFace的大语言模型排行榜上突然出现了一个评分超过LLaMA-65B的大语言模型:Falcon-40B,引起了广泛的关注。本文将简要的介绍一下这个模型。截止2023年5月27日,Falcon-40B模型(400亿参数)在推理、理解等4项Open LLM Leaderloard任务上评价得分第一,超过了之前最强大的LLaMA-65B模型。
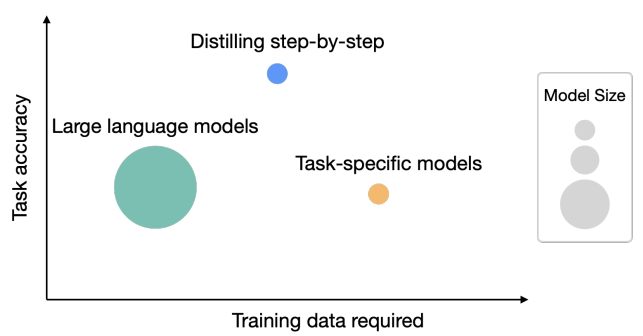
华盛顿大学研究人员与Google的研究人员一起在5月3日公布了一个新的方法,即逐步蒸馏(Distilling step-by-step),这个方法最大的特点有2个:一是需要更少的数据来做模型的蒸馏(根据论文描述,平均只需要之前方法的一半数据,最多只需要15%的数据就可以达到类似的效果);而是可以获得更小规模的模型(最多可以比原来模型规模小2000倍!)
编程大模型是大语言模型的一个非常重要的应用。刚刚,清华大学系创业企业智谱AI开源了最新的一个编程大模型,CodeGeeX2-6B。这是基于ChatGLM2-6B微调的针对编程领域的大模型。