
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




刚刚,吴恩达宣布deeplearning.ai 与 Cohere 合作推出了一个新课程:“Large Language Models with Semantic Search”。这个课程主要教授大家如何使用LLMs进行语义搜索,还提供了大量实践经验,来克服搜索结果和准确性等挑战。
OpenAI宣布发布全新的Diffusion大模型Sora,这是一个可以生成最长60秒视频的视频生成大模型,最大的特点是可以生成非常逼真的电影画面版的视频。
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。
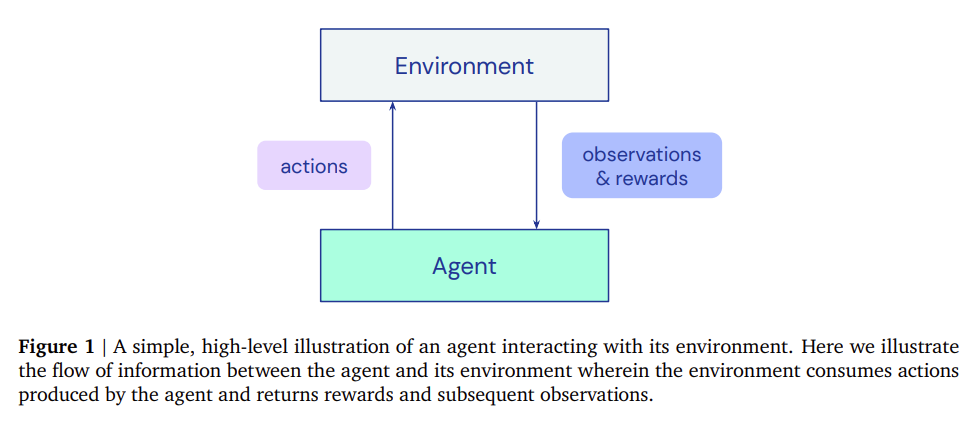
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的
很多算法的开源实现都包含多个文件,因此,学习这些开源代码的时候通常难以找到入口,也无法快速理解作者的逻辑,对于学习的童鞋来说都带来了不小的挑战。这里推荐一个非常优秀的强化学习开源库,它将经典的强化学习算法都实现在一个文件中,想要学习源代码的童鞋只需要看单个文件即可,这就是ClearRL!

Bloomberg在2022年4月开源了Memray,这是一个Python的内存分析器。它可以跟踪Python代码、本地扩展模块和Python解释器本身的内存分配情况。可以看numpy和pandas的运行内存使用。

DALL·E 系列是由 OpenAI 开发的一系列基于大型语言模型的文本到图像生成系统。它们的核心目标是将文本描述转化为高度精确的图像。DALL·E2在2022年4月发布,但是一直没有公开使用,一年半后的2023年9月21日,OpenAI发布第三代DALL·E3,并承诺将与ChatGPT集成。

2023年3月23日OpenAI官方宣布ChatGPT即将支持Plugin模式。这是一种用插件的方式来解锁ChatGPT的能力,包括让ChatGPT可以浏览网页、从本地商店订购食材等。今天,沃顿商学院教授Ethan Mollick在推特上公布了自己收到了ChatGPT内测邀请,并使用它的代码解释器(Python Interpreter)插件让ChatGPT针对一份excel数据完成了非常专业的数据分析的工作。
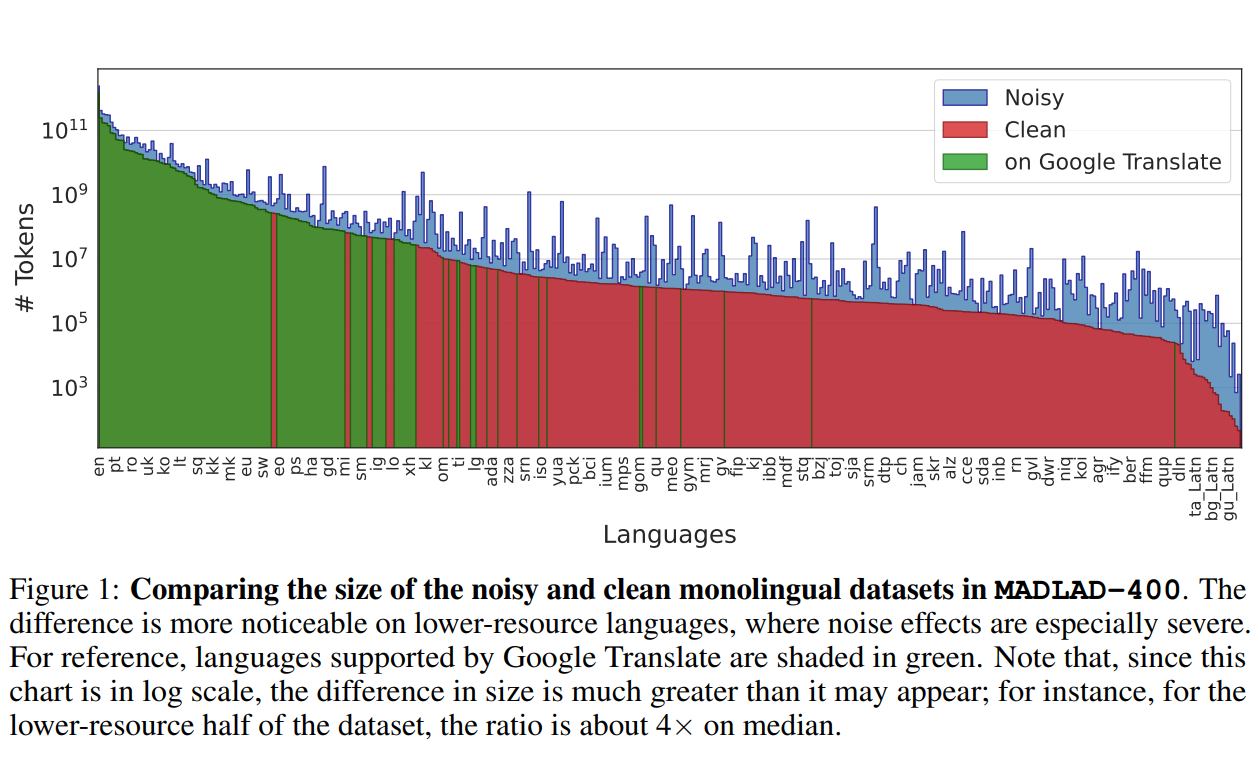
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。
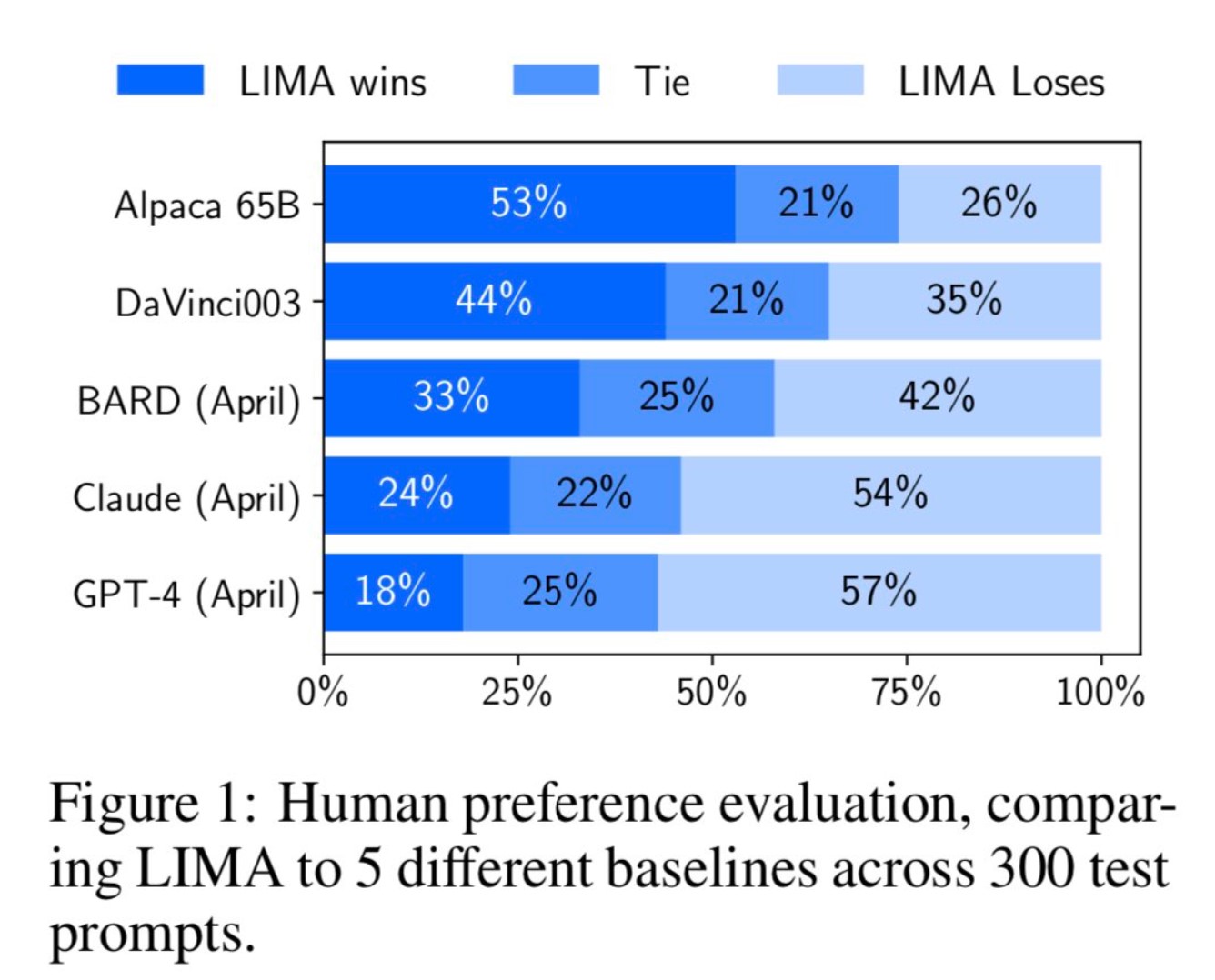
MetaAI最近公布了一个新的大语言模型预训练方法(LIMA: Less Is More for Alignment)。它最大的特点是不使用ChatGPT那样的(Reinforcement Learning from Human Feedback,RLHF)方法进行对齐训练。而是利用1000个精选的prompts与response来对模型进行微调,但却表现出了极其强大的性能。能够从训练数据中的少数几个示例中学习遵循特定的响应格式,包括从规划旅行行程到推测关于交替历史的复杂查询。

重磅福利,斯坦福大学在去年秋季开设了应该是全球第一个transformers相关的课程,授课人员来自OpenAI、Google Brain、Facebook人工智能实验室、DeepMind甚至是牛津大学的业界与学术界的一线大牛。而这两天,这门课相关视频也都公开了,大家可以去观看学习了!
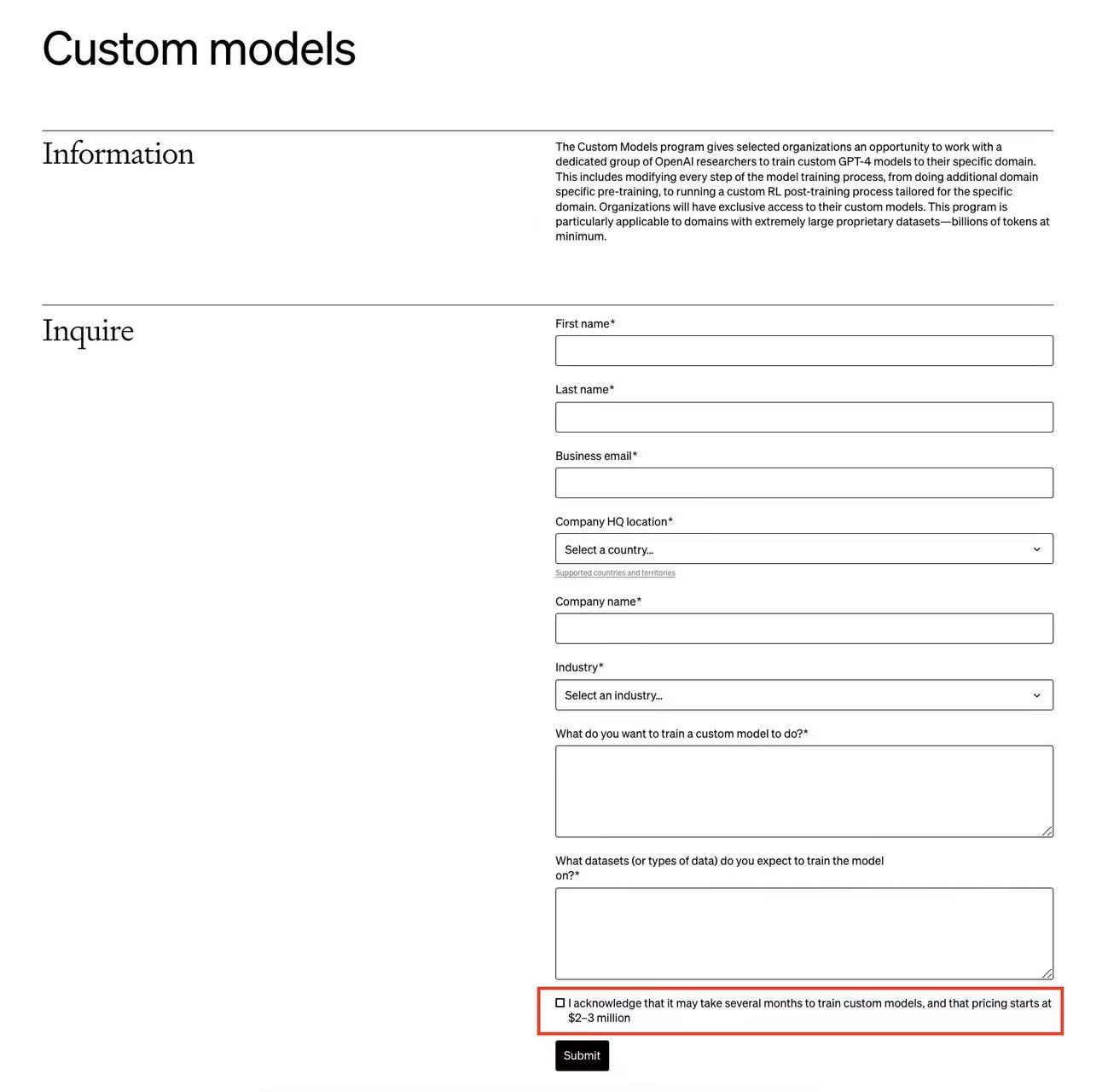
OpenAI的开发者日发布了许多更新。其中,普通用户可以微调GPT-4是非常值得期待的功能之一。但是,OpenAI还有一个针对企业的定制化GPT-4的训练服务,称为Custom Models。而这项为企业单独定制的GPT-4训练服务最新截图显示,需要几个月来训练模型,而且费用是200-300万美元起步!
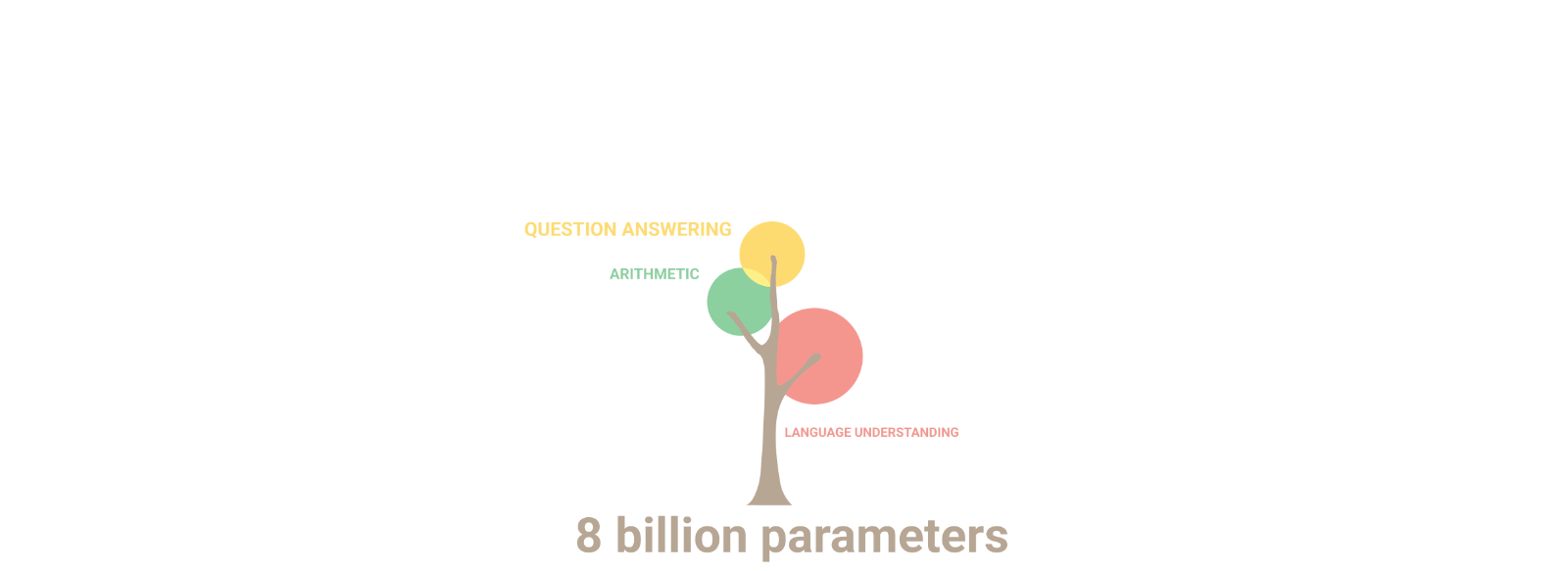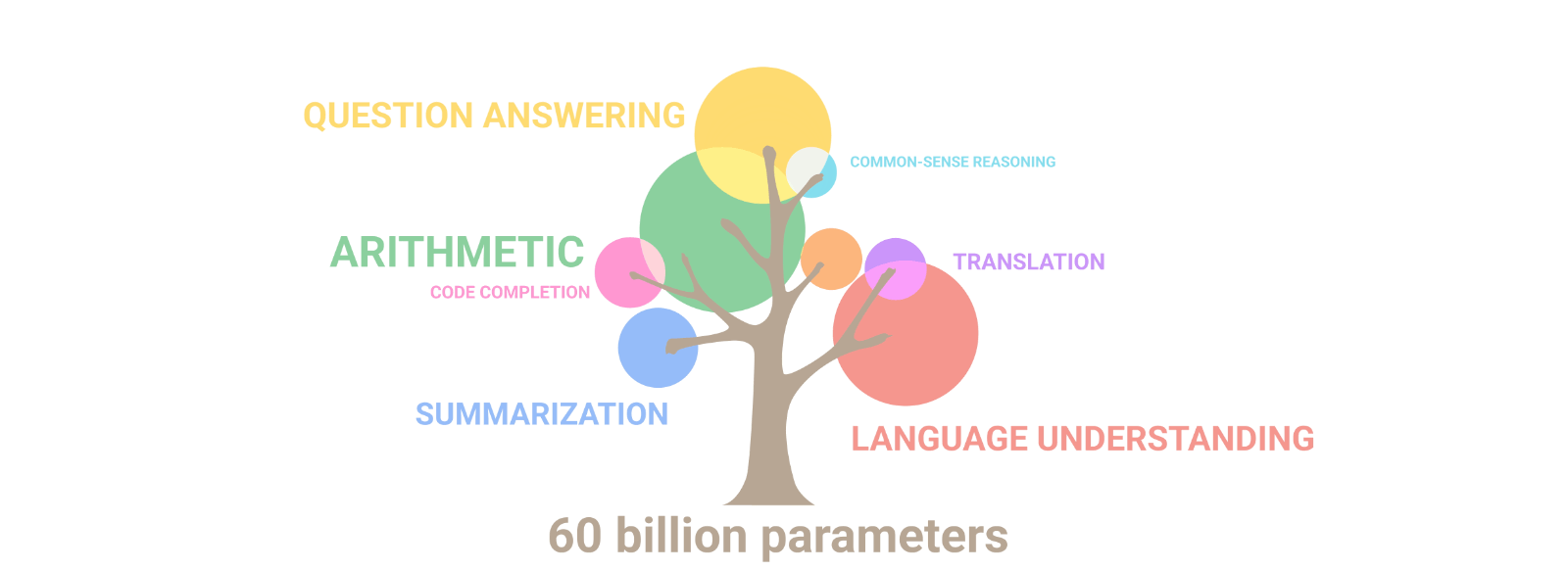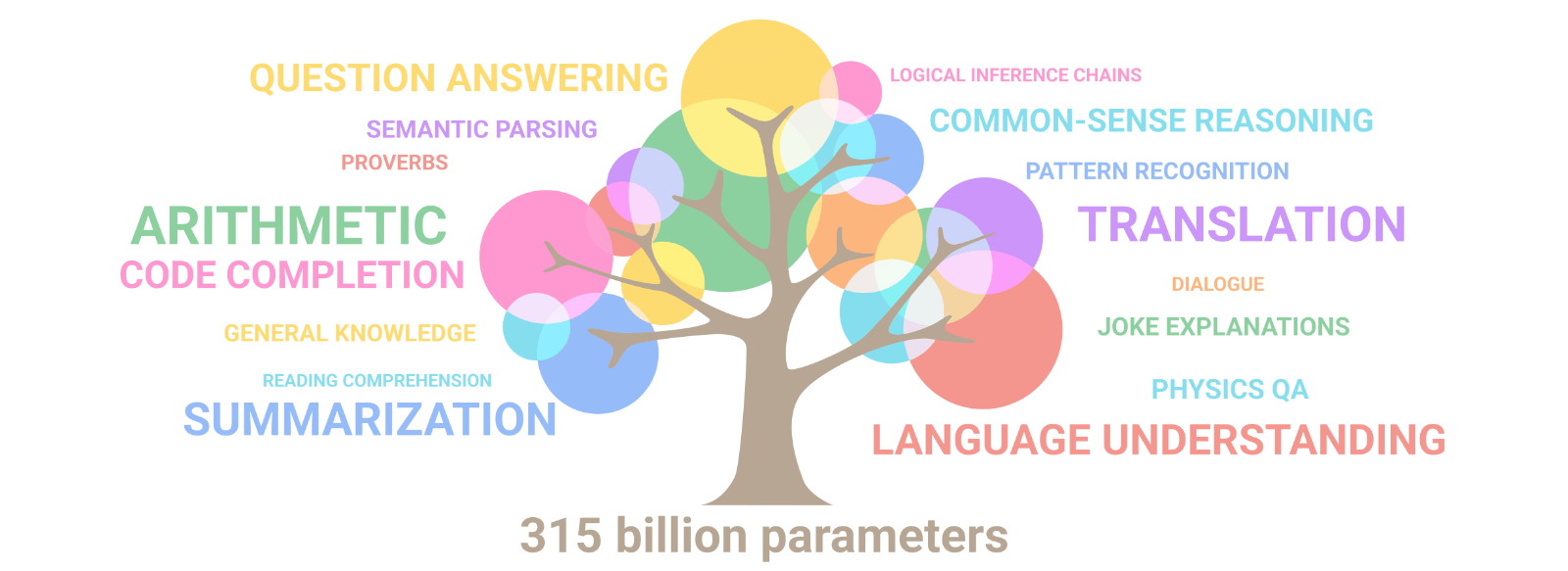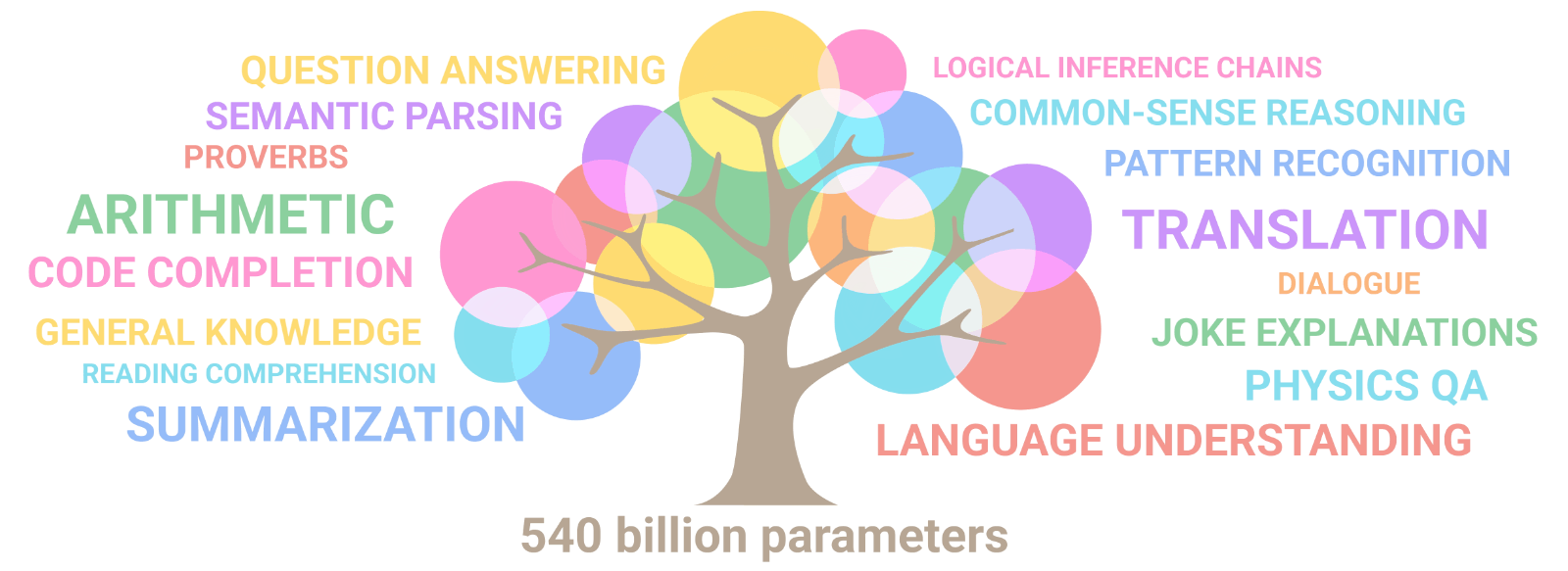
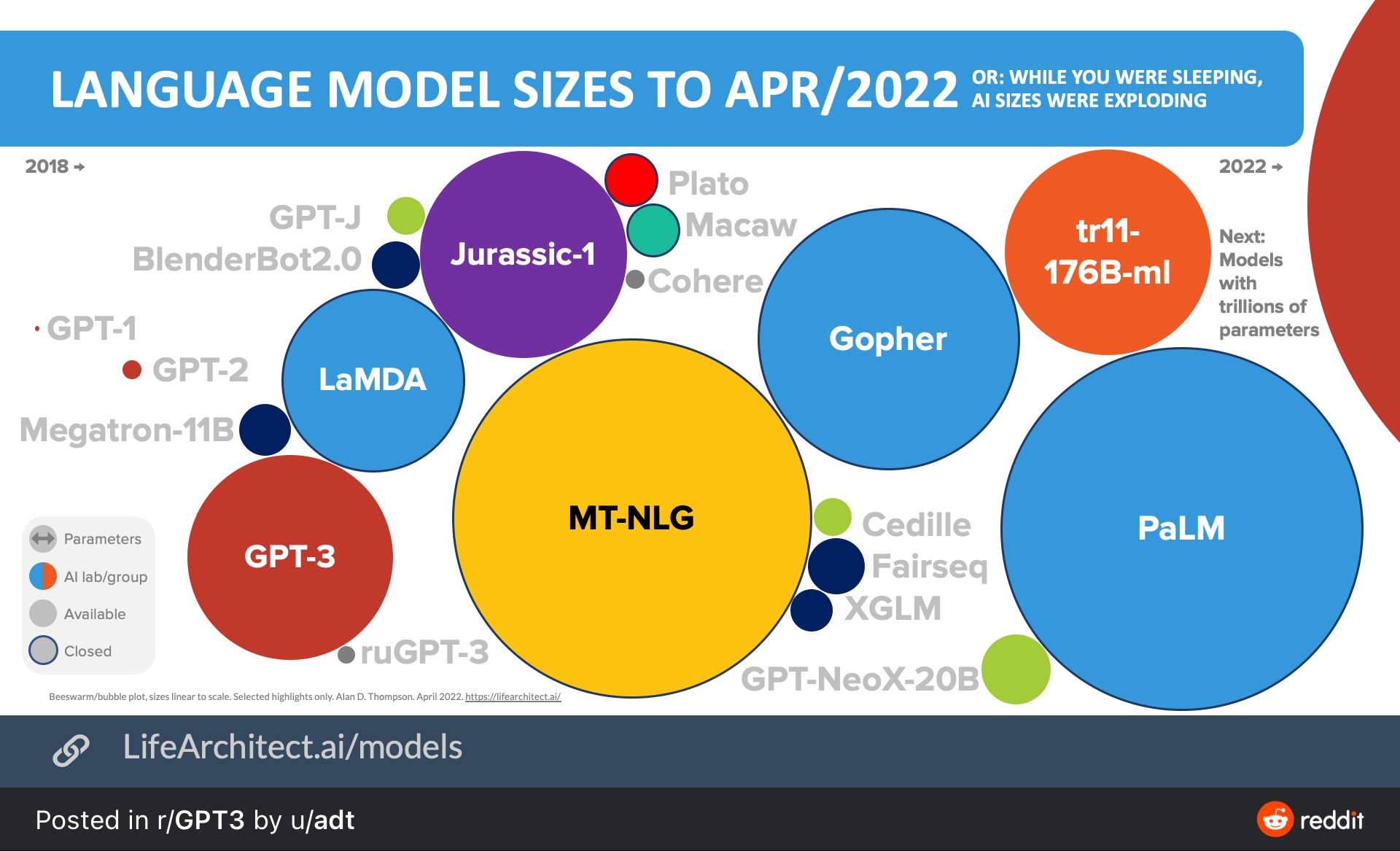
今天,Google介绍了一个新的语言模型,一个Pathways语言模型:PaLM,这是一个用Pathways系统训练的5400亿个参数、仅有dense decoder的Transformer模型,在数百个语言理解和生成任务上对PaLM进行了评估,发现它在大多数任务中实现了最先进的性能,在许多情况下都有显著的优势。
今日推荐
清华大学ChatGLM团队发布AI Agent能力评测工具AgentBench:GPT-4一骑绝尘,chatglm2表现优秀,baichuan-7b排名倒数!
大语言模型的开发者运维LLMOps来临,比MLOps概念还要新:吴恩达联合Google云研发人员推出免费的LLMOps课程
指数分布族(Exponential Family)相关公式推导及在变分推断中的应用
标签平滑(Label Smoothing)——分类问题中错误标注的一种解决方法
即将发布的装备了ChatGPT模型的新版bing都有哪些功能?
MySQL8授权用户远程连接失败,提示ERROR 1410 (42000): You are not allowed to create a user with GRANT