
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。

LiveCodeBench 由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发,是一个先进的评测基准套件,专门用于严格评估大语言模型 (LLMs) 在代码处理方面的能力,并解决现有基准测试的局限性。通过引入实时更新的问题集和多维度评估方法,LiveCodeBench 确保对 LLM 进行公平、全面和稳健的评估。

OpenAI发布的模型中最主要的是大语言模型GPT系列。而且GPT系列模型也在朝着多模态的方向发展。尽管OpenAI有自己的TTS和ASR大模型,但是此前从未正式宣布过。就在今天,OpenAI正式宣布了他们首个语音合成大模型VoiceEngine,该模型也将提供API访问。OpenAI官方的声明中说,现有的基于声音的认证系统应该被淘汰掉!因为已经不安全了!

今天微软宣布,新版本的Bing将全线接入ChatGPT,试图领先谷歌一步。这篇博客将总结一下带了ChatGPT的新版本Bing将有哪些新功能!

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。

Llama系列是MetaAI开源的大语言模型,是全球开源大模型中最重要的力量之一。第一代的Llama系列模型不允许商用,第二代模型则放松了范围,允许商用。而Llama系列模型因为优秀的品质,也是许多开源模型的基座。而今天Llama3即将发布。
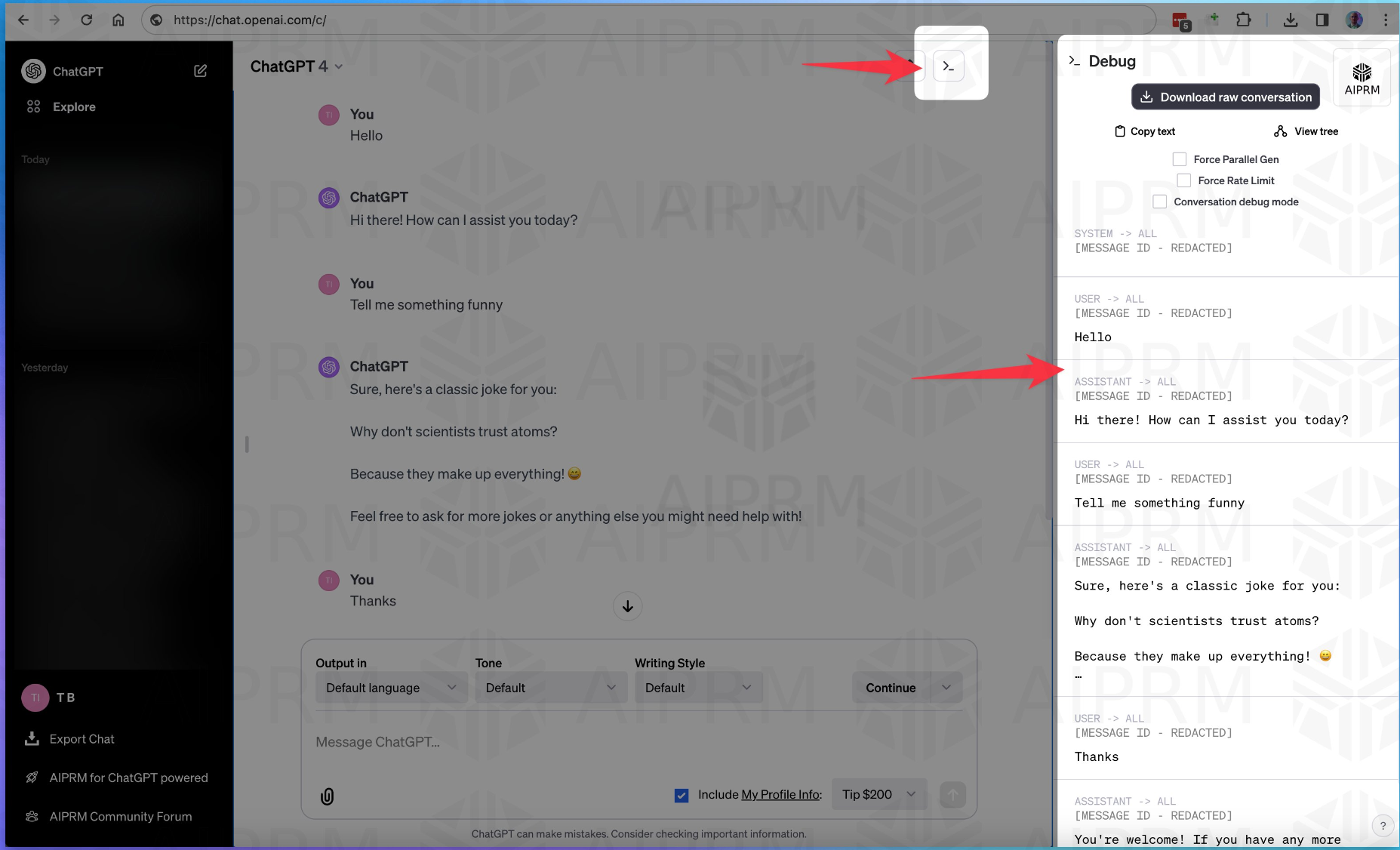
AIPRM的工作人员最近发现ChatGPT的客户端隐藏内置了一个新的debug特性,可以提高ChatGPT对话的问题调试功能。这个特性包含非常多的功能。同时,最新的截图显示ChatGPT Team版本计划可能延迟但没有取消。

今天,OpenAI在其官网上发布了一个全新的研究成果:一个利用较弱的模型来引导对齐更强模型的能力的技术,称为由弱到强的泛化。OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。因为彼时,人类的水平不如AI系统,所以可能无法再对模型输出的内容评估好坏。为此,OpenAI提出这种超级对齐技术,希望可以用较弱的模型来对齐较强的模型。这样可以在出现比人类更强的AI系统之后可以继续让AI模型可以遵循人类的意志、偏好和价值观。
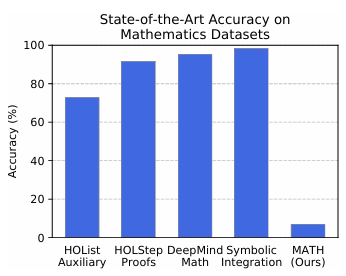
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。

Grok系列是马斯克旗下的人工智能企业xAI发布的大语言模型,在推特上给大家使用。第一个版本,Grok-1前端时间 开源,效果一般。就在刚才,xAI宣布他们开始内测Grok-1.5,即将全面商用!

在去年末的OpenAI宫斗风波中,伴随着Sam下台和重新掌权过程中有一个非常重要但不被大家了解的算法Q*。国外的路透社曾经提到OpenAI内部一个称为Q*(Q Star)项目取得了非常重大的突破,使得部分人认为AGI很接近,进而引发了一系列事件。但是,Q*到底是什么?是否存在一直被很多人猜测。而最近,一个神秘的帖子继续爆料了Q*的信息。

在过去的几年里,我们看到了AI在图像、视频和文本生成方面的巨大进步。然而,音频生成领域的进展却相对滞后。MetaAI这次再为开源贡献重磅产品:AudioCraft,一个支持多个音频生成模型的音频生成开发框架。
近几年人工智能的发展已经让大家感受到AI算法不再是实验室的小玩具,它对社会和生活的影响已经在逐步显现。仅几年的AI模型如ChatGPT、DALL·E2、StableDiffusion等都是生成式模型,即基于无标注数据训练的可以根据输入观测数据的模型。而生成式AI平台可能是未来最重要的一种平台能力。本文是由Matt Bornstein, Guido Appenzeller, and Martin Casado等人发布的介绍当前生成式AI平台的相关企业。

虽然LLM在很多任务上很好用,但是实际应用中我们常见的文本分类、文本标注等工作目前却依然缺少一个可以利用LLM能力的好方法。LLM的强大并没有在工程落地上比肩传统的机器学习处理框架。上周,一个叫Scikit-LLM新的开源项目发布,将传统优秀的Scikit-learn框架与LLM结合,带来了LLM落地的新方法。

Gemini是谷歌发布的一系列大模型的名称,是谷歌前期大模型Bard产品的替代品。从Gemini 1.0发布开始,每一次发布都获得了不错的反响。今天,Google发布了最新一代的Gemini 2.0模型,首个产品是其参数规模较小的Gemini 2.0 Flash,它的推理速度是Gemini 1.5 Pro的2倍,但是各项评测结果上的表现却超过了Gemini 1.5 Pro。该模型完全免费提供给大家使用。
今日推荐
缺少有标注的数据集吗?福音来了——HuggingFace发布few-shot神器SetFit
2022年9月份最火的10个AI研究——基于GitHub的Star数量排序
GPT-4来了!微软德国CTO透露GPT-4将是多模态模型,并于下周发布!
加州大学欧文分校信息技术办公室开放基于GPT-4.5的ZotGPT服务测试
谷歌发布新一代大模型Gemini 2.5 Flash,成本、速度和性能的最优均衡,同时支持推理和非推理模式,评测结果超Sonnet 3.7
CerebrasAI开源可以在iPhone上运行的30亿参数大模型:BTLM-3B-8K,免费可商用,支持最高8K上下文输入,仅需3GB显存
pandas.DataFrame.to_csv和dask.dataframe.to_csv在windows下保存csv文件出现多个换行结果