
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




OpenAI 于 2025 年 2 月 27 日发布了 GPT-4.5,作为其语言模型系列的最新版本。尽管具体的技术细节因商业保密而未完全公开,基于现有信息和合理推测,DataLearner提供更具体的数据和分析,同时补充更多来自用户的评价。
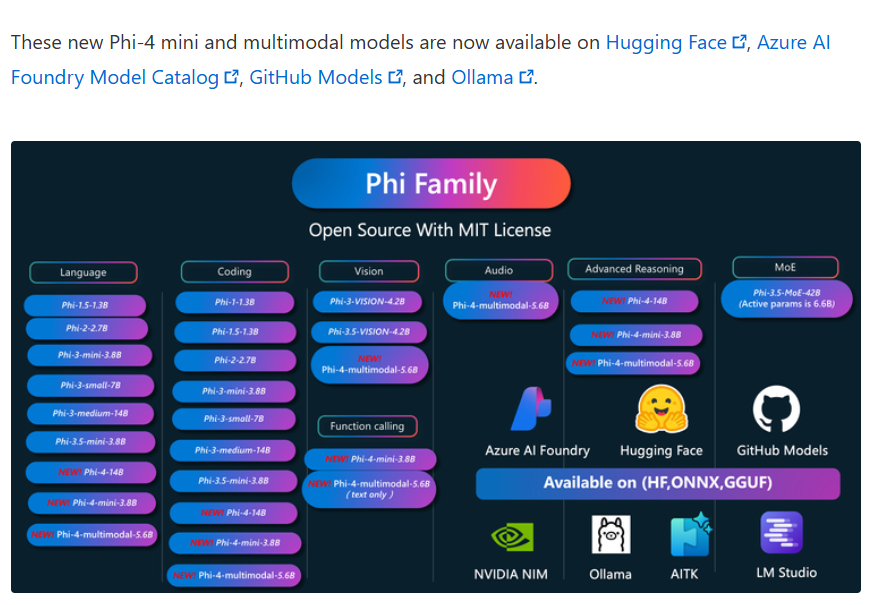
2025年2月27日,微软正式发布了其全新系列的大型语言模型——Phi-4系列。这一系列包含了三个创新性的模型:Phi-4-Mini、Phi-4-Multimodal和一款经过推理优化的Phi-4-Mini。此次发布的模型不仅在性能上展现出色,更在多模态能力与推理任务中实现了显著突破。其中,Phi-4-Multimodal是一个仅仅包含56亿参数规模的多模态大模型,但是支持文本、语音、图片的输入,十分强大。
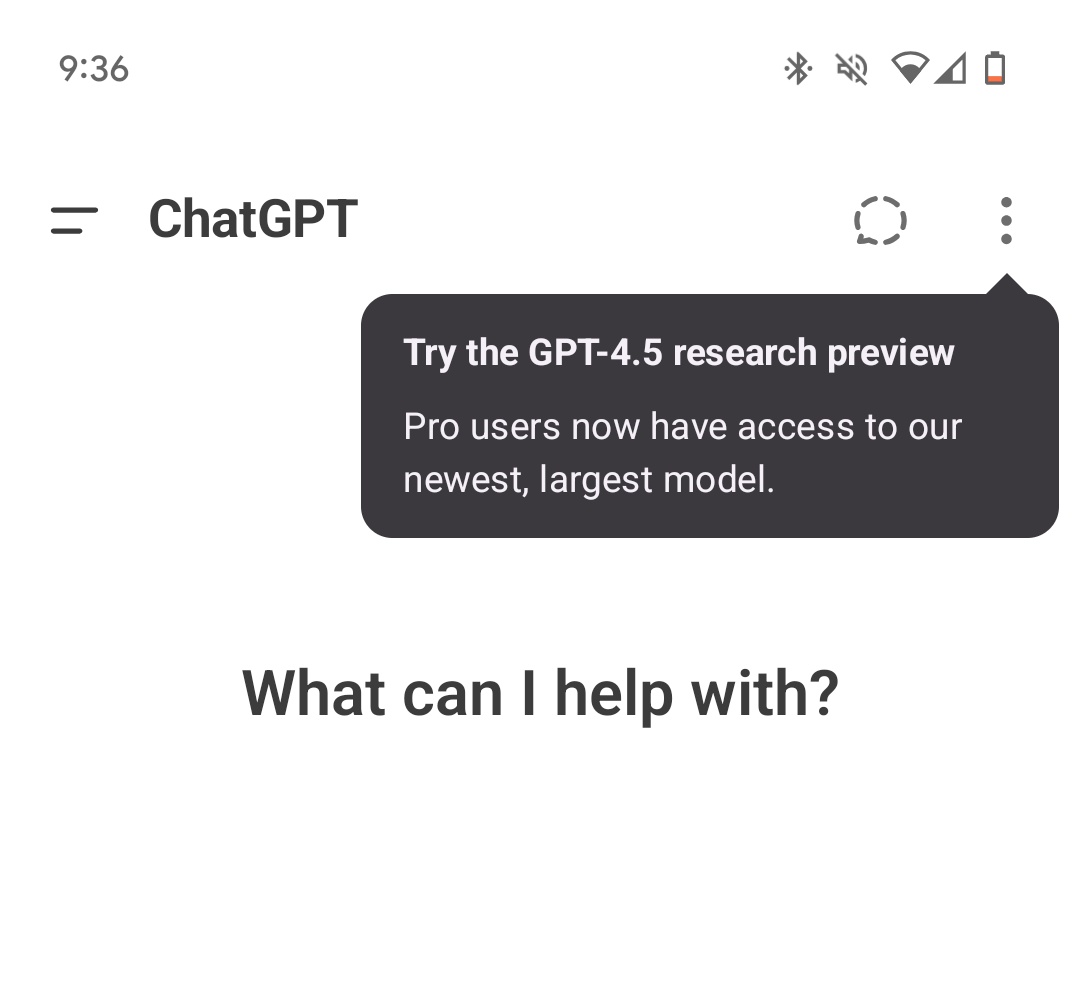
最近,一张截图在网络上流传,显示OpenAI安卓客户端的应用字符串文件(strings.xml)中出现了关于GPT-4.5的相关描述。这一发现引发了广泛关注,暗示OpenAI可能即将推出其最新的大型语言模型——GPT-4.5。该信息最早由开发者 @bitbor91 发现并分享,截图内容似乎来自ChatGPT安卓客户端的应用资源文件。

2025年2月25日,Anthropic发布了Claude 3.7 Sonnet大模型,该模型是业界第一个同时支持标准输出和深度推理模式的单一大模型,各项评测相比较Claude Sonnet 3.5大幅提升。特别是代码能力进一步增强。
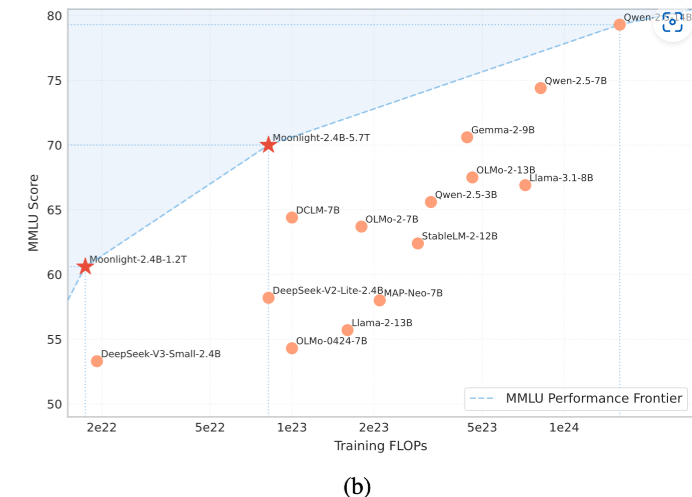
月之暗面(Moonshot AI)是此前中国大模型企业中非常受关注的一家企业。旗下的Kimi大模型和产品因为强悍的性能、超长的上下文以及非常快速的响应引起了广泛的关注。不过,此前MoonshotAI的策略一直是闭源模型,但是产品免费。也许是受到了DeepSeek的压力,月之暗面在2025年2月23日首次开源了旗下的一个小规模参数的大语言模型Moonlight-16B。

短短两年间,AI技术的进步为软件工程带来了新的可能性。然而,这些模型在真实世界的软件工程任务中究竟能发挥多大的作用?它们能否通过完成实际的软件工程任务来赚取可观的收入?为了验证大模型解决真实任务的能力和水平,OpenAI发布了一个全新的大模型评测基准SWE-Lancer来评测大模型这方面的能力。
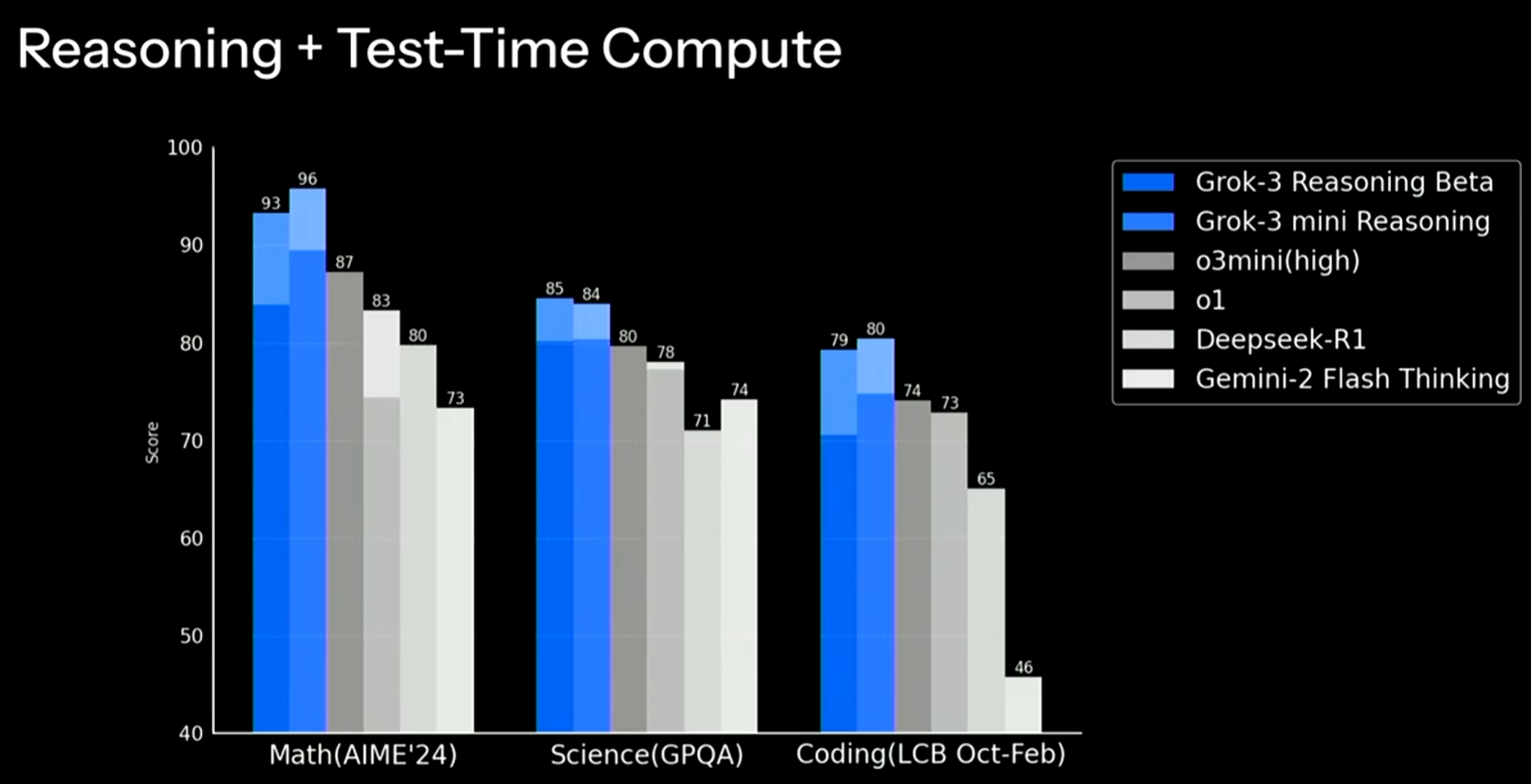
今天马斯克旗下的xAI公司发布了最新一代大语言模型Grok3,基于20万张GPU集群训练,各方面的提升都非常明显。在主流评测上都超过了现有的大模型。
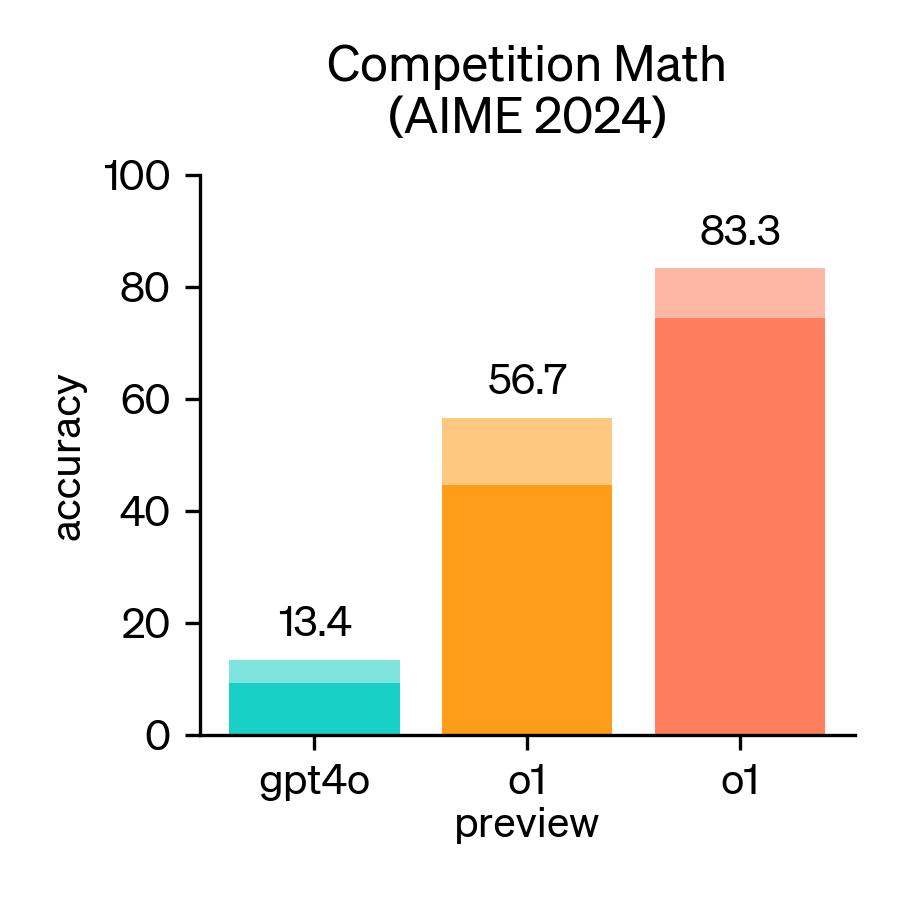
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。

最近,一些未公开但即将发布的内容被曝出,显示出Anthropic正在为其AI模型(Claude)推出一项名为Thinking的新功能。这一功能将极大提升AI在推理和决策时的透明度,允许用户查看AI的思考过程,并提供更长时间的推理分析,帮助用户更好地理解和验证AI的决策逻辑。
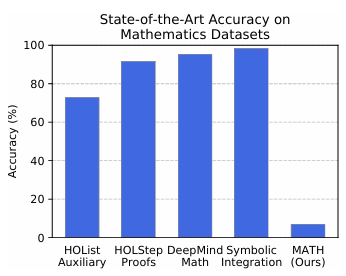
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。

随着DeepSeek R1和OpenAI的o1、o3等推理大模型的发布,我们当前可使用的大模型种类也变多了。但是,推理大模型和普通大模型之间并不是二选一的关系,在不同的问题上二者各有优势。为了让大家更清晰理解推理大模型和普通大模型的应用场景。OpenAI官方推出了一个推理大模型最佳实践指南。描述了二者的对比。本文将总结这份推理大模型最佳实践指南。
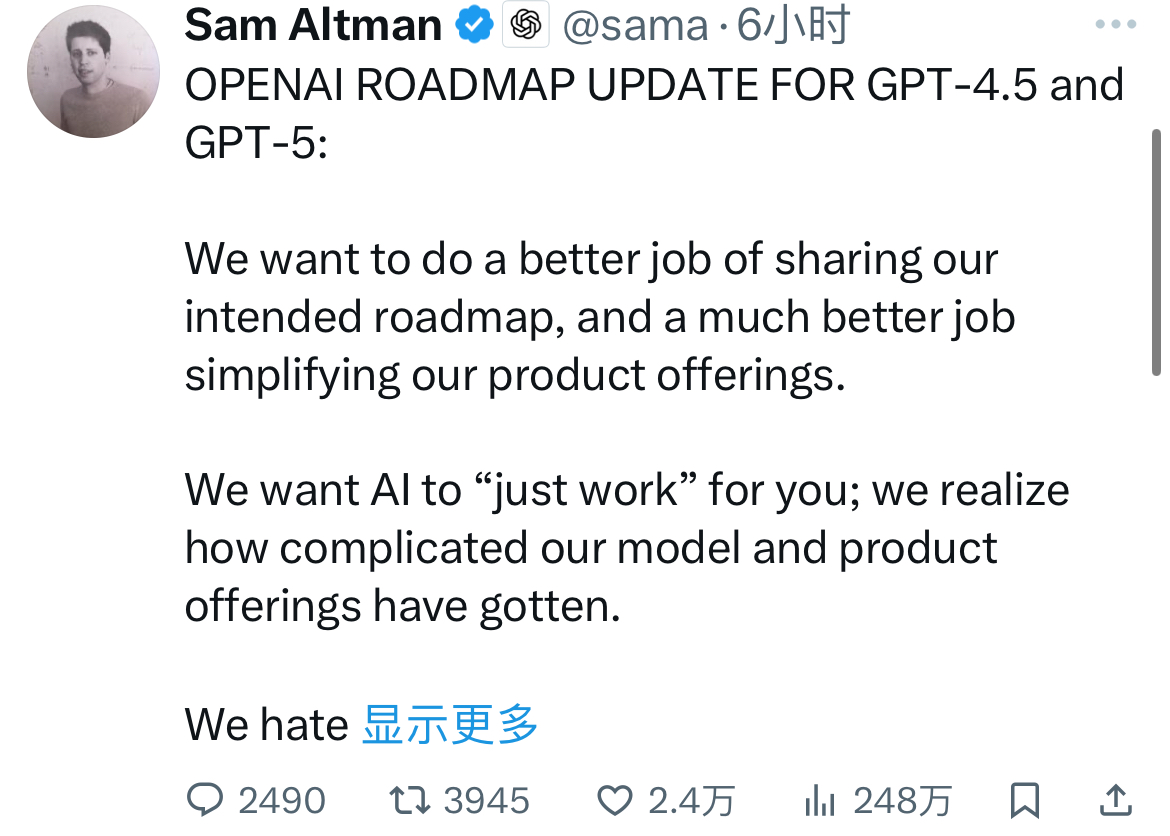
三个小时前,Sam Altam在推特上说明了OpenAI未来的大模型路线图。比较重磅的消息是即将在未来几周发布GPT-4.5,并且在几个月后发布GPT-5。
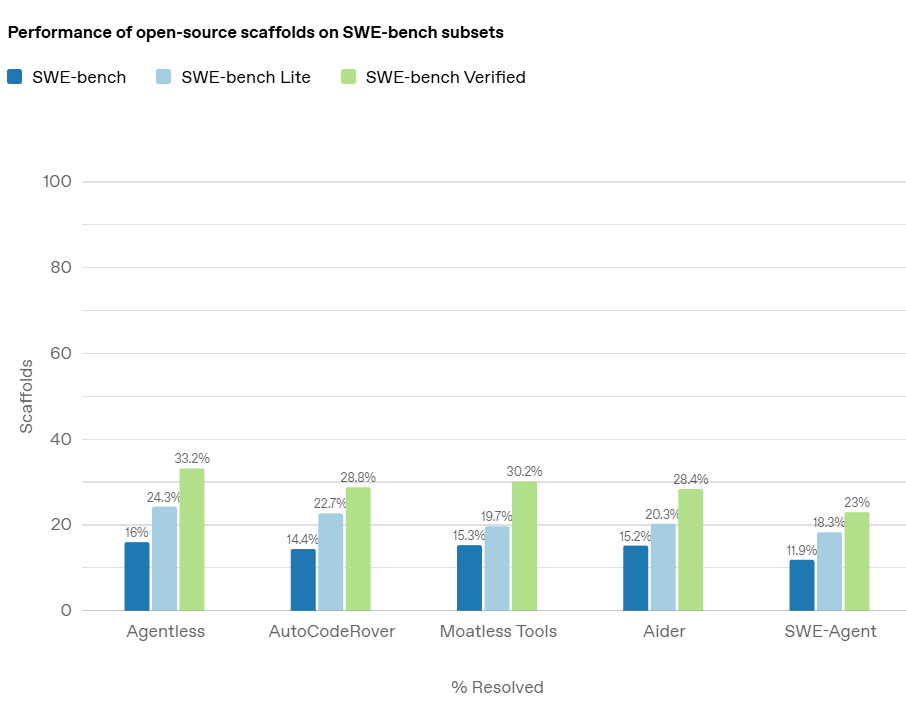
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 *SWE-bench Verified* 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
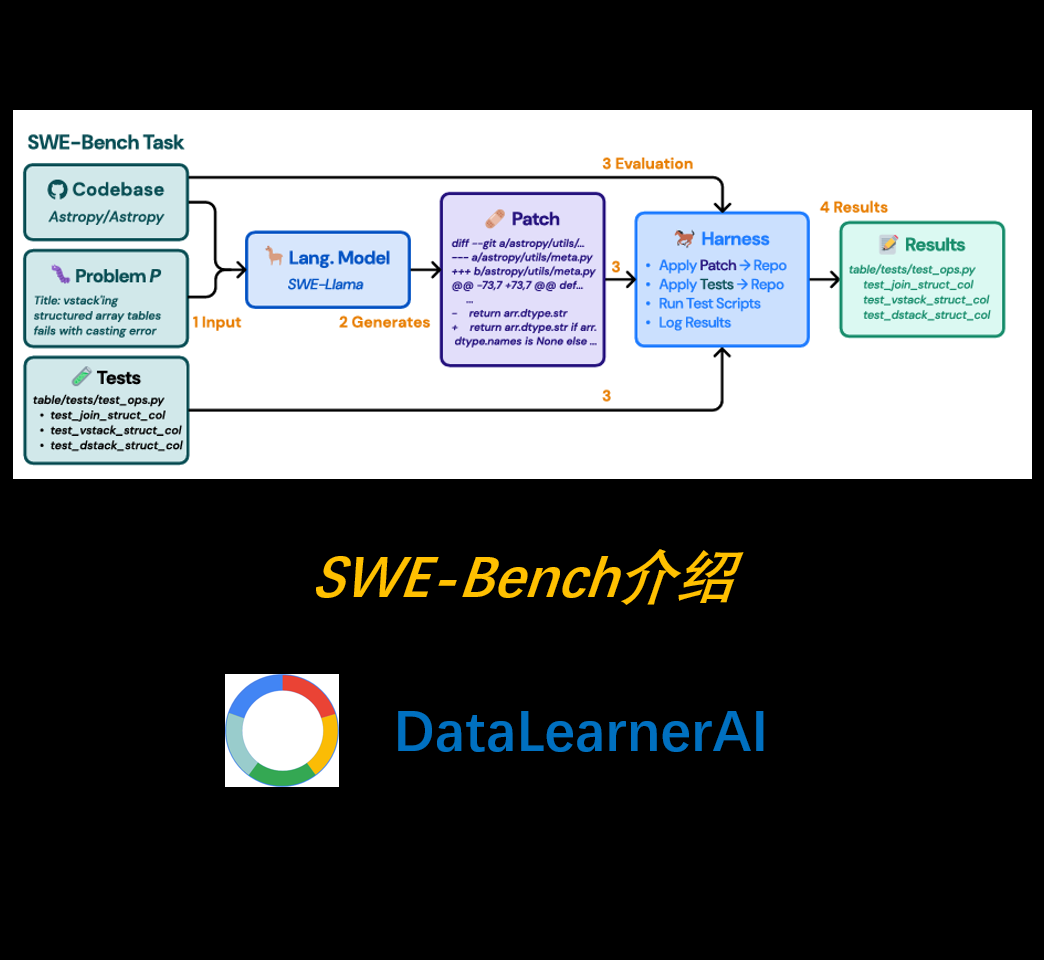
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于**自包含的、较短的代码生成任务**,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——**SWE-Bench**,旨在测试 LLM 在**真实软件工程问题**中的能力。
今日推荐
大模型领域最著名开源模型小羊驼Vicuna升级!Vicuna发布1.5版本,可以免费商用了!最高支持16K上下文!
重磅优惠!打1折!OpenAI开放最新的GPT-3.5和ChatGPT模型API商业服务!
超越Cross-Entropy Loss(交叉熵损失)的新损失函数——PolyLoss简介
2023年4月业界发布的重要20多个AI模型总结:OpenAssistant、Segment Anything Model、StableLM、AudioGPT等
开源大语言模型再次大幅进步:微软团队开源的第二代WizardLM2系列在MT-Bench得分上超过一众闭源模型,得分仅次于GPT-4最新版