
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




很多童鞋在查询期刊的时候会发现某些期刊不是SCI(SCIE)索引,而是一个叫ESCI的索引。这似乎有点像SCI,但好像又有区别,所以大家会有疑问,本篇博客将解释二者的区别。

pandas.get_dummies是pandas中一种非常高效的方法。它最主要的作用是可以将分类变量转变成dummy变量,也就是虚拟变量。这篇博客将简要的介绍一下pandas.get_dummies()方法,并描述其在机器学习中的应用的一些注意事项。

当前的大语言模型主要是预训练大模型,在大规模无监督数据上训练之后,再经过有监督微调和对齐之后就可以完成很多任务。尽管如此,面对垂直领域的应用,大模型依然需要微调才能获得更好地应用结果。而大模型的微调有很多方式,包括指令微调、有监督微调、提示工程等。其中,指令微调(Instruction Tuning)作为改进模型可控性最重要的一类方法,缺少深入的研究。浙江大学研究人员联合Shannon AI等单位发布了一篇最新的关于指令微调的综述,详细描述指令微调的各方面内容。
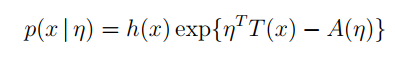
指数分布族(Exponential Family)相关公式推导及在变分推断中的应用

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。
在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,可以提高模型效果。
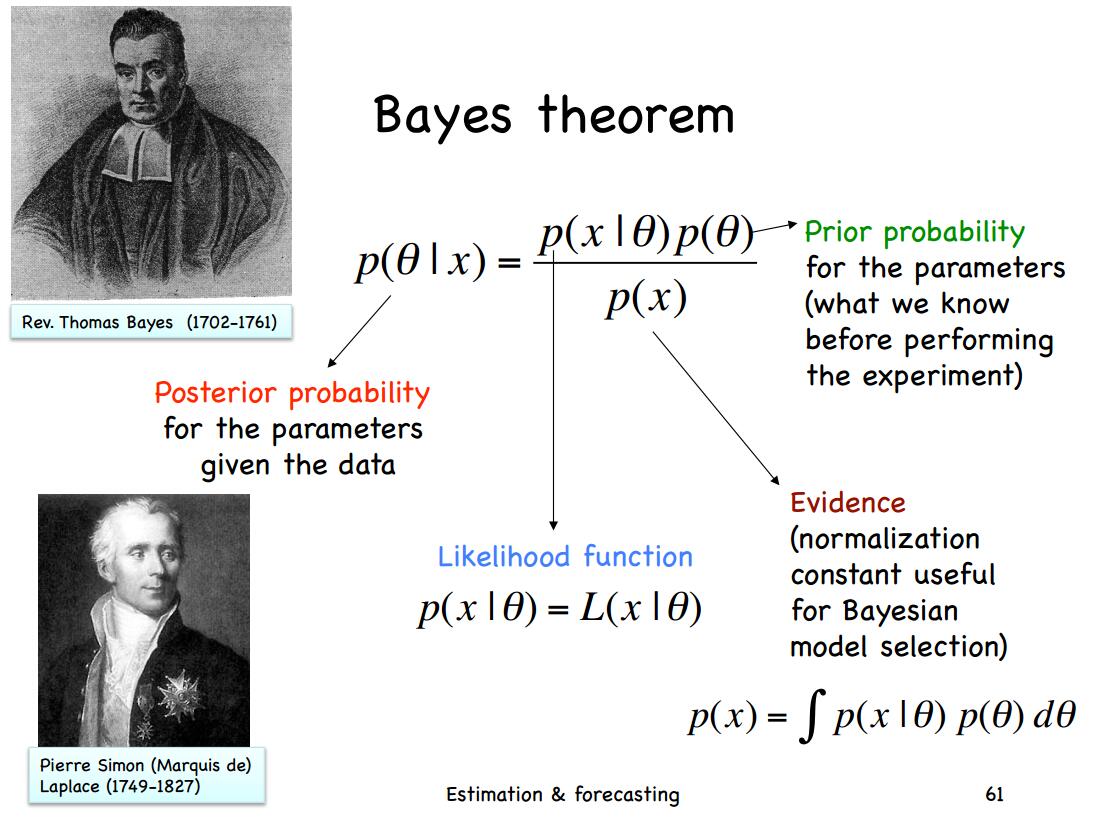
多元正态(高斯)分布分布是我们最常用的分布之一,这篇博客的主要内容来自Will Penny的文章的翻译。主要讲述关于多元正态分布的贝叶斯推导


Hugging Face是一家非常活跃的人工智能创业公司。它拥有一个非常强大并且活跃的人工智能社区。有超过5000多家机构都在Hugging Face的社区发布内容,包括Google AI、Facebook AI、微软等。自从2016年成立以来,这家企业经历了5轮融资,总共募集了6000万美金。本文将简要介绍这家企业相关的信息。
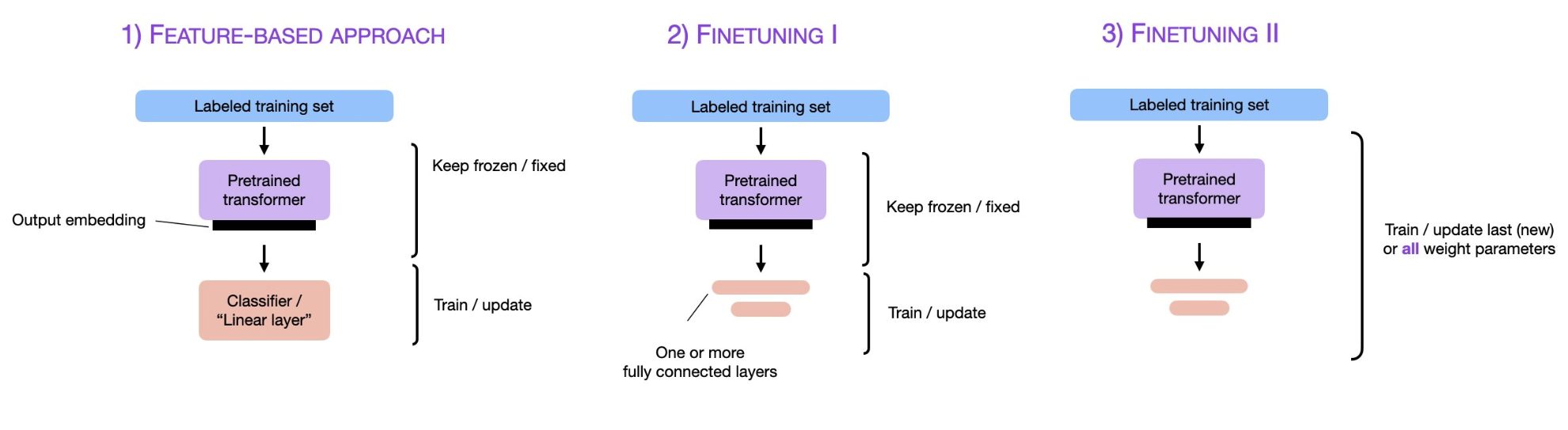
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。

深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。
KKT条件(Karush–Kuhn–Tucker conditions)是求解带不等式约束的最优化问题中非常重要的一个概念和方法。这篇博客将解释相关概念和操作。