
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




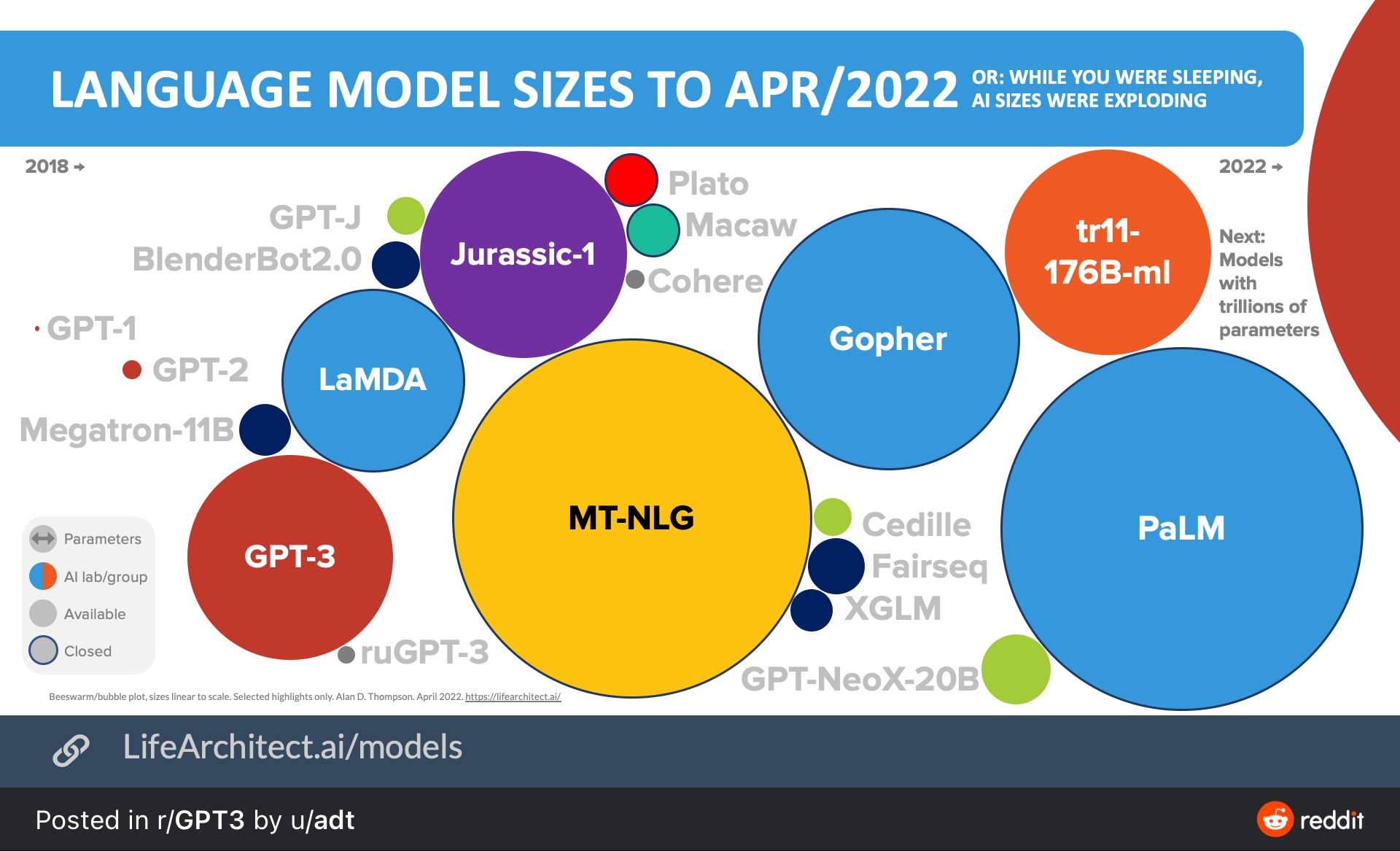
关注深度学习或者NLP的童鞋应该都知道openAI的GPT-3模型,这是一个非常厉害的模型,在很多任务上都取得了极其出色的成绩。然而,OpenAI的有限开放政策让这个模型的应用被限定在很窄的范围内。甚至由于大陆不在OpenAI的API开放国家,大家几乎都无法使用和体验。而五一假期期间,FaceBook的研究人员Susan Zhang等人发布了一个开源的大预言模型,其参数规模1750亿,与GPT-3几乎一样。

Google旗下自动驾驶公司Waymo的研究人员Mingxing Tan发现了一个可以替代Cross-Entropy Loss的新的损失函数:PolyLoss,这是发表在ICLR 22的一篇新论文。什么都不变的情况下,只需要将损失函数的代码替换成PolyLoss,那么模型在图像分类、图像检测等任务的性能就会有很好的提升!
很多算法的开源实现都包含多个文件,因此,学习这些开源代码的时候通常难以找到入口,也无法快速理解作者的逻辑,对于学习的童鞋来说都带来了不小的挑战。这里推荐一个非常优秀的强化学习开源库,它将经典的强化学习算法都实现在一个文件中,想要学习源代码的童鞋只需要看单个文件即可,这就是ClearRL!
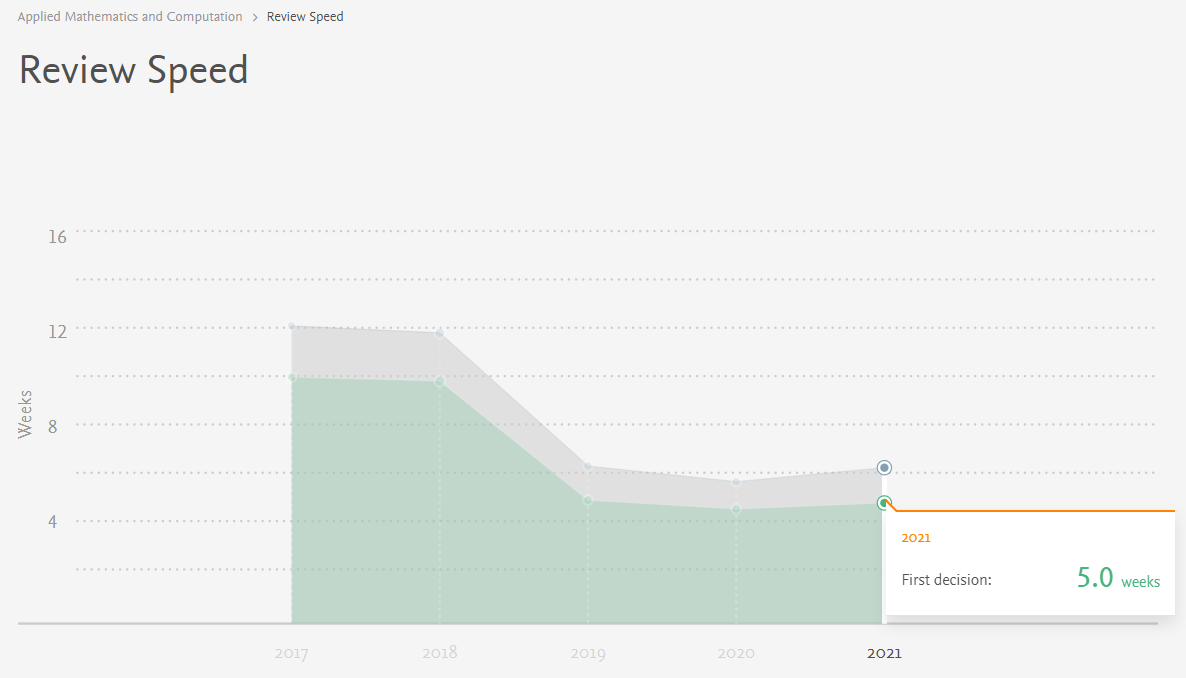
科研成果发表速度对于国内的硕士生和博士生来说非常重要,它涉及了同学们的毕业、出国和奖学金等。很多童鞋在投稿之前都希望了解期刊的审稿周期。虽然大多数期刊没有规定明确的审稿时间,但是,随着大家对学术期刊投稿周期的关注,很多学术期刊也开始就自己的审稿速度开始有所要求,本文针对常见的期刊审稿周期提供一个普遍的分析方法。

开源软件在现代互联网技术的发展中扮演者重要的作用。很多技术的进步和发展都是由开源软件推动的。而开源软件的发展离不开背后强大的开源组织的管理。本文列举最著名的五个开源组织,简述其背景,欢迎大家阅读。

使用AI技术预测未来、对数据进行分类可以解决很多个人或者小企业的问题。然而,对于新手和非行业的小企业来说,学习或者雇佣一个专业人才解决这些问题似乎有些得不偿失。这里给大家推荐一个给新手的可视化的机器学习模型训练网站,可以让大家都能享受到AI技术带来的红利。

Bloomberg在2022年4月开源了Memray,这是一个Python的内存分析器。它可以跟踪Python代码、本地扩展模块和Python解释器本身的内存分配情况。可以看numpy和pandas的运行内存使用。
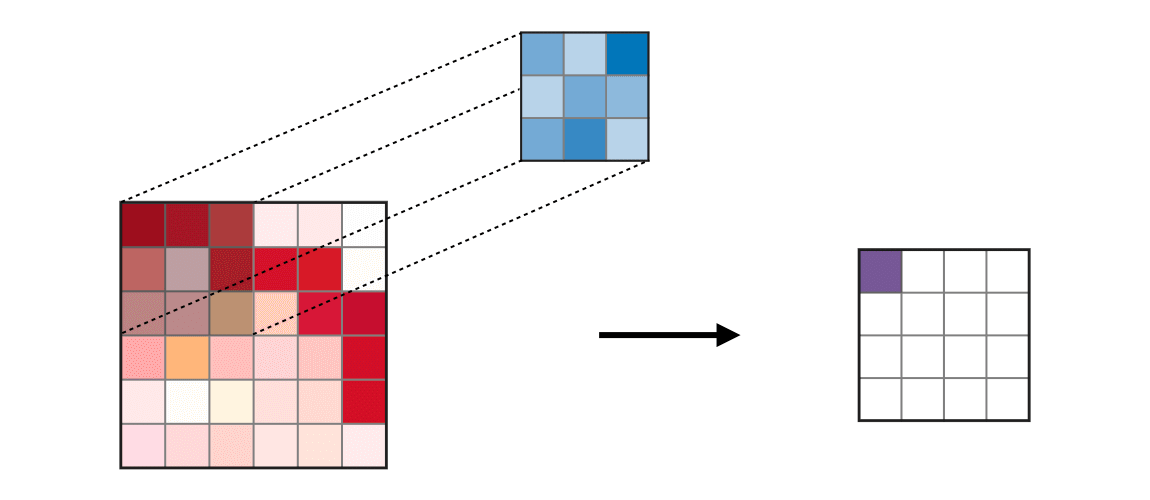
CS 230 ― Deep Learning是斯坦福大学视觉实验室(Stanford Vision Lab)的Shervine Amidi老师开设的深度学习课程,他在课程网站上挂了一个关于深度学习示意图的网站,这里面包含了各种深度学习相关概念的示意图和动图,十分简单明了。


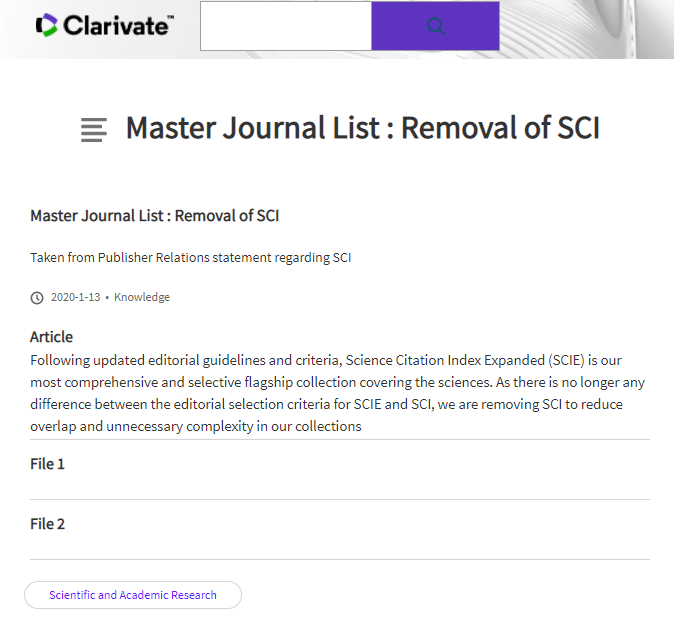
很多童鞋在查询期刊的时候会发现某些期刊不是SCI(SCIE)索引,而是一个叫ESCI的索引。这似乎有点像SCI,但好像又有区别,所以大家会有疑问,本篇博客将解释二者的区别。
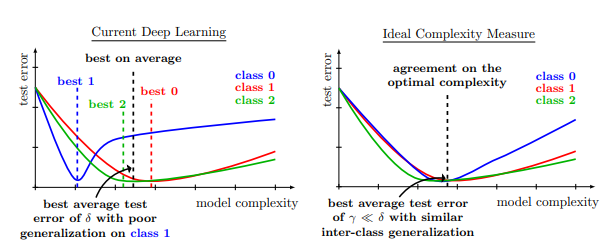
正则化是一种基本技术,通过限制模型的复杂性来防止过度拟合并提高泛化性能。目前的深度网络严重依赖正则化器,如数据增强(DA)或权重衰减,并采用结构风险最小化,即交叉验证,以选择最佳的正则化超参数。然而,正则化和数据增强对模型的影响也不一定总是好的。来自Meta AI研究人员最新的论文发现,正则化是否有效与类别高度相关。